According torecent research, 16% of the people between 16 and 65 in Amsterdam have low literacy skills. This hinders societal participation in tasks such as voting, paying taxes, reissuing documents, or applying for social benefits. Thus, as part of ourAmsterdam for Allproject, we have set on a mission to research the use of AI for measuring and improving the readability of municipal communication. In this blog post, we summarize our findings so far and dive into Eliza Hobo’s methodology for contextualized lexical simplification, or simply said, substituting complex words within the context of a sentence.
Language Level
There are plenty ofchallenges that editors facein their writing process, which prevent them from delivering simple texts - a broad audience with different requirements, tight deadlines, or lack of time or colleagues to review every piece, among others. Furthermore, multiple aspects can make a text complex - the structure, the language, and even the underlying content itself. When it comes to the used language, some common issues include the use of passive voice, vague statements, or complex words, as in the following sentence:
The Municipality of Amsterdam hasguidelinesthat help people write in a clear and understandable language. However, the number of rules and the linguistic background necessary to implement them make following these guidelines impractical and nearly impossible for people without communications training. Thus, a platform that automatically helps people in their writing process could help our colleagues avoid common mistakes. Such a platform could help editors in multiple ways - it can signify whether the text is on the desired level, it can highlight issues within the text and, ideally, it can provide suitable alternatives that the editors can choose to use.
In the past, we already experimented with the first step - that is,automatically assessing the language levelof Dutch municipal text. This project revealed a lack of Dutch resources related to language level and text simplification. While stimulating the creation of more related corpora (such as thisCEFR datasetcontaining texts from Gemeente Amsterdam among others), we decided to move on and explore the next step: providing simplification suggestions.
Together withEliza Hobo, we started our simplification journey with a single concrete task - simplifying complex words within a sentence. These words can be uncommon, archaic, foreign, or jargon, such as those in thelist of difficult words.
This task, called lexical simplification, is traditionally solved using diverse language resources such as lists of synonyms or paraphrasing databases. Unfortunately, such resources are scarce for less common languages such as Dutch. Furthermore, even if they existed, they don’t always contain specific terminology related to topics important to the municipality, like taxes, healthcare or housing. Finally, these approaches usually provide simplifications outside of the context of the sentence, often resulting in suggestions that don’t fit the structure or meaning of the sentence, as in the following example:
Example of substitutions provided by looking up (some of) the synonyms of the word “pilot” within the WordNet database. The synonym sets (known as synsets) can also be viewed online.
Thanks to recent advances in language modeling, such as theBERTmodel [1], Qiang et al. proposed anew approachthat addresses some of these challenges - a model called Lexical Simplification Bert, or LSBert [2]. This state-of-the-art simplification approach identifies complex words, then generates substitutions of the complex word and finally ranks the substitute candidates. One of the drawbacks of this approach is that the generated substitutions are not necessarilysimpleralternatives.
In hermaster thesis, Eliza built upon LSBert targeting two issues. First, she attempted to tackle the generation ofsimpleralternatives by using different fine-tuning techniques. Second, she adapted the entire pipeline to Dutch, and more specifically, to the simplification of Dutch municipal texts.
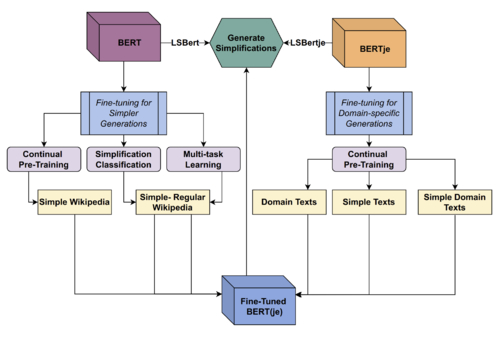
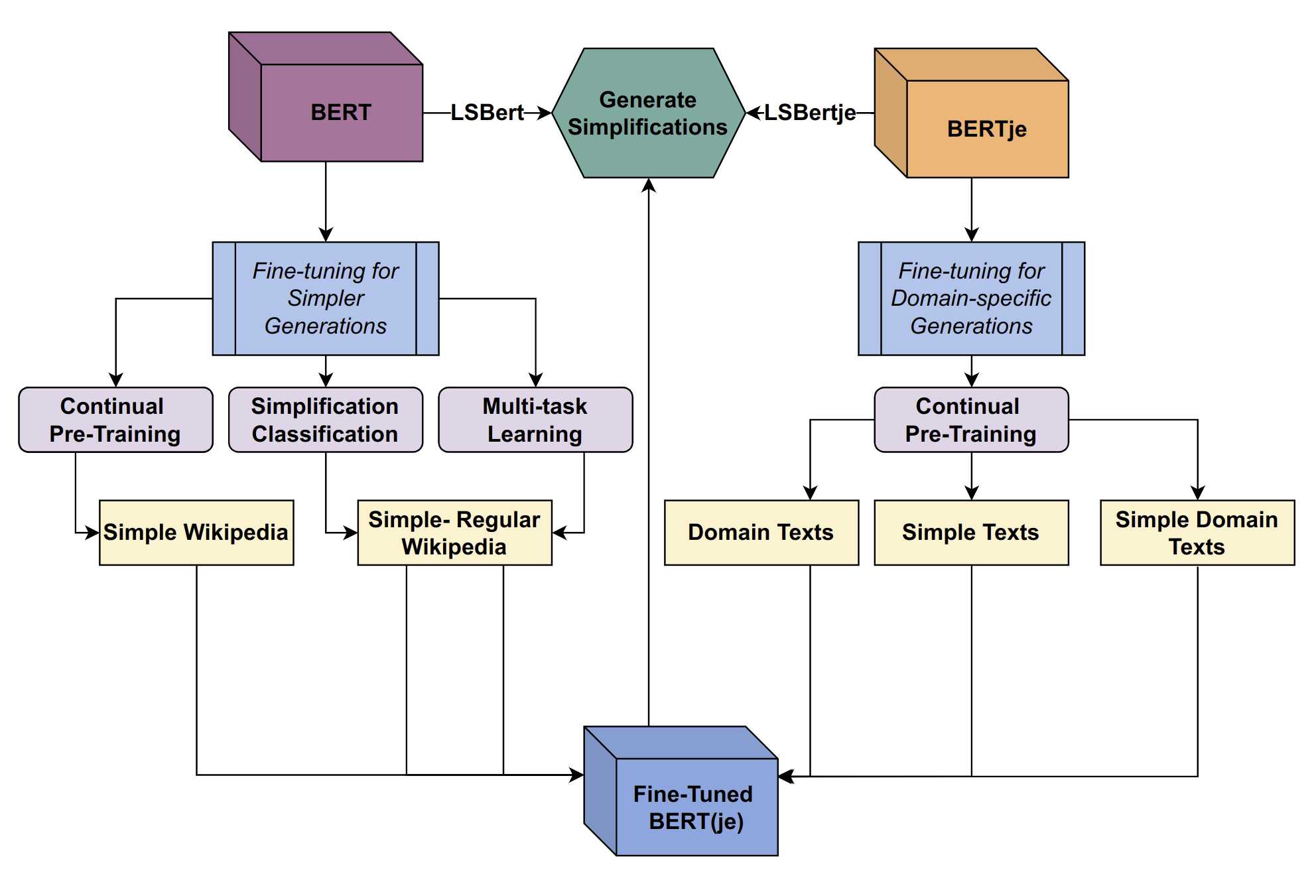
A diagram depicting the experiments conducted as part of Eliza’s thesis. On the left: experiments targeting the generation of simpler alternatives using English benchmark datasets. On the right: experiments related to the simplification of Dutch municipal texts. Source: Simply Accessible
Fine Tuning for Simpler Alternatives
There are multiple ways of using language models for lexical simplification. LSBert uses BERT for the so-called masked token prediction - that is, present the model with a sentence where a single word (in this case the complex word) is masked; then the task of the model is to predict which one is the masked word. In order to steer the model into predicting a word that fits the sentence not only syntactically but also semantically, they prepend the original sentence (including the complex word).
An example of input to LSBert: a sentence, followed by a separating [SEP] token and a repetition of the sentence with the complex word (bear) masked under a [MASK] token.
However, this setup does not ensure that the predicted word would be less complex than the original. To tackle this issue, Eliza experimented with a few modifications to the original model. These modifications were based on the assumption that showing simpler texts to the model would help it generate simpler substitutions. First, the original model could be fine-tuned by continuing the training cycle using the simple texts fromSimple Wikipedia, and still performing the task of predicting masked tokens within those sentences. Alternatively, it could be trained to classify simple or complex sentences froma corpus of aligned sentencesfrom (the more complex) Wikipedia and Simple Wikipedia [3]. Unsurprisingly, the combination of these two tasks yields the best results.
An interesting finding from the analysis of the best-performing model shows that the fine-tuning strategy does help generate more frequently used words, which are assumed to be simpler and easier to understand.
Domain Adaptation to Dutch Municipal Texts
Next, LSBert was adapted to the task of lexical simplification for Dutch by making use of a Dutch version of the Bert model -BERTje[4]. This time, experiments were conducted by fine-tuning the model on simple Dutch data from theWablieft corpus, as well as (simple) municipal data provided by the communications department of the municipality.
In order to quantitatively evaluate the Dutch model, a new dataset* was manually annotated by 23 communications and language experts. The annotators were presented with a list of words generated by a baseline model and asked to select all good simplifications or provide their own suggestions. It is worth mentioning that 77% of the respondents found that most of the time at least one good simplification was already provided by the initial model.
Examples of sentences and the automatically generated substitutions for a highlighted complex word.
The performance of the models trained by the three different fine-tuning strategies was similar, reaching a potential of 85% - a measure for how often at least a single suitable substitution has been generated. These overall results prove that it is possible to generate simplifications for words within Dutch municipal texts. As can be seen in the examples above, the generated alternatives could easily serve as help for editors within a simplification platform.
Next Steps: Towards Automatic Text Simplification
Currently, we are taking yet another step further, researching the technological possibilities for automatic text simplification - that is, to simplify longer pieces of text, such as whole sentences or even paragraphs.Daniel Vlantis, a bachelor student from VU, is working on replicatinga pipeline for the simplification of dutch medical texts[5]. The main idea behind this work is to overcome the issues presented by the lack of Dutch training data for the task. His initial experiments show that this pipeline might also be applicable to general municipal communication.
Stay tuned for Daniel’s full methodology and all results soon!
* Both the lexical simplification evaluation dataset and the corpus of simple municipal documents are availableon requestfor research purposes. All code is publicly available in the project’sGitHub repository.
[1] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[2] Qiang, Jipeng, et al. "Lexical simplification with pretrained encoders." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 05. 2020.
[3] Coster, William, and David Kauchak. "Simple English Wikipedia: a new text simplification task." Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. 2011.
[4] De Vries, Wietse, et al. "Bertje: A dutch bert model." arXiv preprint arXiv:1912.09582 (2019).
[5] Evers, Marloes. Low-Resource Neural Machine Translation for Simplification of Dutch Medical Text. Diss. Tilburg University, 2021.