Recently, the City of Amsterdam has been using urban point clouds as a data source for a variety of projects. Urban point clouds are a valuable data asset for the City because they hold high quality and rich information on assets in the public space. Previous projects that utilized urban point clouds as data source to extract useful information about the city include the detection of overhanging street lights and cables and extraction of venue accessibility.
Another key interest of the City is to semantically segment urban point clouds to generate mappings of urban topographical object properties. From these mappings, useful insights can be gathered. For example, information on the region-based density of parked cars or misalignment of traffic lights on roadsides can be collected. An example of a segmented urban point cloud is shown in figure 1.
To generate semantic mappings from point clouds, semantic segmentation models can be applied. The goal of these segmentation models is to correctly assign each point in the point cloud a semantic label. This semantic label describes the semantic class a point belongs to. To be able to correctly assign these labels, segmentation models randomly sample points in point clouds. Subsequently, the spatial and/or color information of these points is utilized to learn a discriminative point feature which is used to classify the point.
Figure 1. Example of segmented urban point cloud.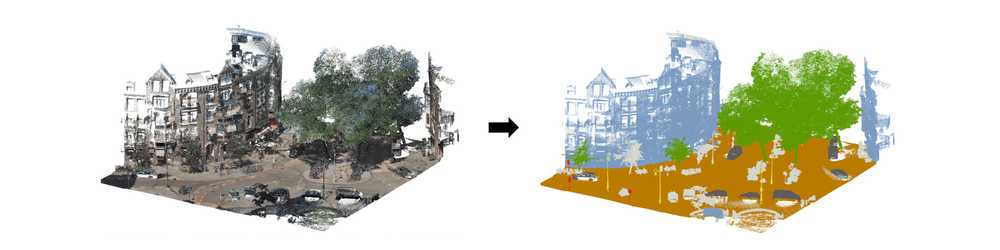
A difficulty when training semantic segmentation models on urban point clouds to generate semantic mappings of the city, however, is that urban point clouds are frequently affected by class imbalance. Class imbalance refers to the situation where certain classes dominate others. For example, most points in points clouds that are collected in Amsterdam belong to big objects and surfaces like buildings and roads, while the number of points belonging to relatively small objects in point clouds such as rubbish bins is significantly lower. These circumstances complicate the learning of useful features for points belonging to minority class objects since there is less data to learn from. Accordingly, the segmentation quality of minority class objects is relatively low (see figure 2). Existing methods like importance sampling and global augmentation could be applied to resolve the class imbalance problem. However, due their speed and efficiency limitations, these are usually impracticable to apply to large-scale imbalanced urban point clouds.
Figure 2: example of how class imbalance can affect segmentation quality of minority class objects. The well-represented ground points are segmented almost perfectly, while almost all minority class rubbish bin points are misclassified as car points.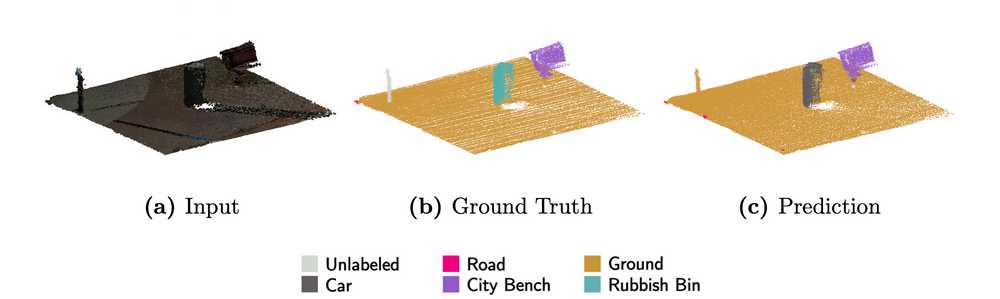
Motivated by the fact that the City of Amsterdam is interested in generating high quality semantic mappings of the city using segmentation models, but this procedure is affected by class imbalance and existing solutions to this problem show limitations, the goal of this project was to develop an efficient method to encounter the class imbalance problem in semantic segmentation of urban point clouds. To this end, we developed Multi-Scale Object-Based Augmentation (MOBA). This is a memory-efficient method to improve the segmentation quality of minority class objects in urban point clouds.
In this blog post, we first explain the MOBA framework. Second, we elaborate on the experimental setup that was used to test MOBA. This includes a description of the utilized point cloud dataset, deployed deep-learning-based semantic segmentation models and evaluation metrics. Third, we present and discuss the results. We conclude this blog post with a reflection on the results and recommendations for future work.
Multi-Scale Object-Based Augmentation (MOBA)
MOBA is an augmentation technique specifically designed to increase the semantic segmentation performance of deep-learning-based models on objects belonging to minority classes. In general, MOBA comprises three steps, which are stated below:
- MOBA locates minority class objects in the training set using DBSCAN (Density-Based Spatial Clustering of Applications with Noise). DBSCAN is a density-based clustering algorithm. It is very suitable to find objects from minority classes as it can discover clusters of any arbitrary size and shape, even if noise and outlier points are present. Since DBSCAN is only applied to the training data, the ground truth labels of points can be used to find clusters of points that represent a minority class object.
- Point clouds are cropped around objects belonging to minority classes that are found with DBSCAN. Crops are generated using different radii. Cropped tiles with relatively small radii allow the model to frequently subsample points from minority class objects to learn descriptive features from their textures. Cropped tiles with larger radii enable the model to train on additional minority examples while preserving the global environment information around an object of interest, supporting the learning of more global object textures.
- The cropped tiles are added to the training dataset as additional examples. These additional examples allow the semantic segmentation model to learn more discriminative features for points that belong to minority classes. Subsequently, the segmentation quality of these classes can be improved.
Figure 3: A visualization of MOBA applied to a city street light with four radii: 1.5, 2.5, 5 and 10 meters. For distinctiveness, the streetlight has been marked yellow.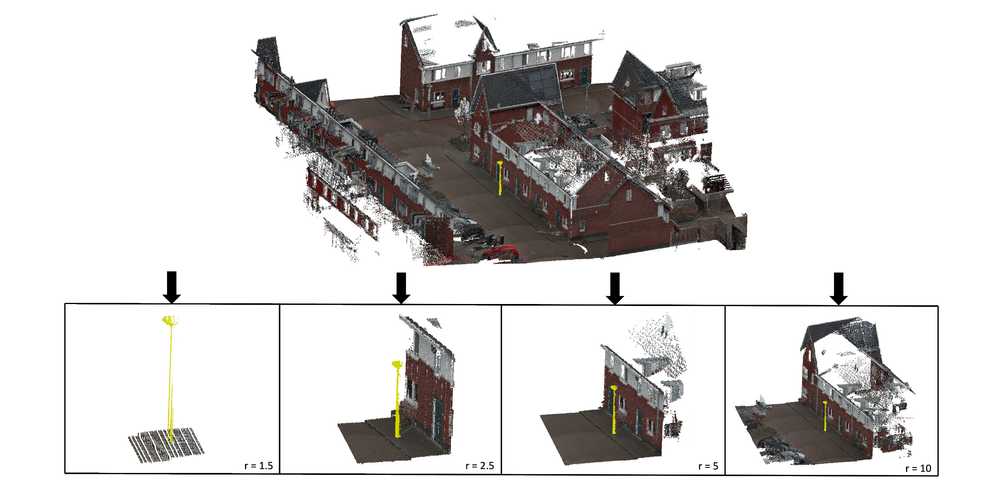
MOBA can be considered as an efficient method to improve the semantic segmentation quality of minority class objects for two reasons: (1) the method does not add to the computational complexity of the model compared to alternative sampling methods like importance sampling and (2) the additional memory required for the augmented tiles is limited as only small cropped tiles are added to the dataset. This memory efficiency is beneficial when working with limited memory resources and large-scale urban point cloud datasets that can easily reach hundreds of gigabytes.
Dataset
A large-scale imbalanced urban point cloud dataset of Amsterdam named Amsterdam3D was utilized to test MOBA. This dataset consists of 140 point cloud tiles of 50m x 50m. By default, each point in the dataset holds geographic (i.e., X,Y,Z coordinate values), multi-spectral (i.e., R,G,B color values) and intensity (i.e., a reflectance value) information. In total, there are 10 semantic classes. An overview of these classes and the imbalanced distribution of points over these classes are shown in table 1 and figure 4, respectively.
Table 1: Quantitative representation of Amsterdam3D dataset. Number of points is given in millions.
Figure 4: Distribution of points over all scans in Amsterdam3D dataset. Scale is logarithmic.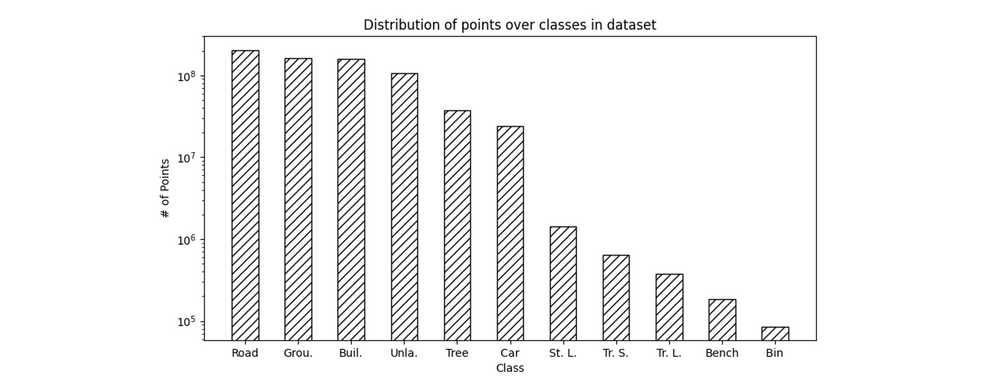
Semantic Segmentation Models
Three models named RandLA-Net, SCF-Net, and CGA-Net were deployed to test and evaluate MOBA. The reason these models were utilized is twofold. Firstly, the proposed models have proven their power on multiple benchmark datasets by reaching remarkably high performance compared to other models. Secondly, their random sub-sampling architecture to learn point features allows the processing and segmentation of the large-scale urban point cloud dataset we used. In contrast, many competitors cannot handle such data due to memory limitations.
Metrics
Intersection over Union (IoU) and mean Intersection over Union (mIoU) were used as the primary evaluation metrics. IoU measures the fraction of correctly classified points in class c over the total number of points classified as class c or belonging to class c. mIoU is the average mIoU over all classes. The IoU and mIoU formulas are given in equations 1 and 2. Furthermore, mean precision (mP) and mean recall (mR) were also included as evaluation metrics.
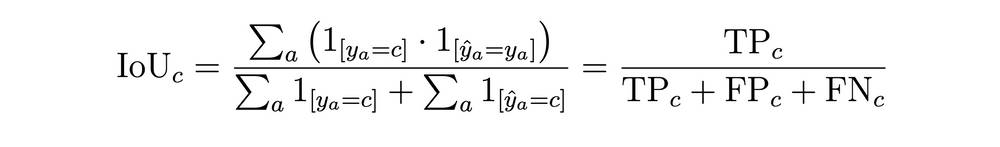
Equation 2: mean IoU.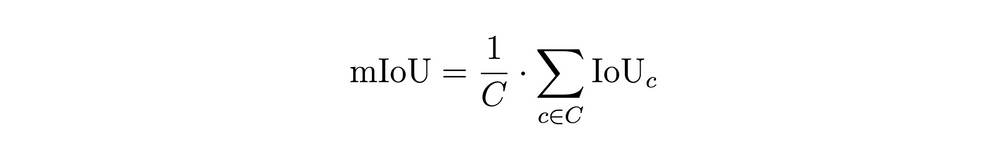
Results
Table 2 shows the quantitative results of MOBA. As can be seen, the IoU of multiple minority classes (e.g., street light, street sign, traffic light and rubbish bin) show significant improvements in IoU when MOBA was applied. Specifically, the rubbish bin class shows remarkable increases from 15.1% up to 78.1% in IoU. Furthermore, the mR score is highest across all models when MOBA is applied. This characteristic can be considered desirable since a decrease in false negatives (i.e., a higher mR) suggests that all models generate better point features to correctly identify most points, including minority class points.
Table 1: Quantitative semantic segmentation results without and with MOBA on Amsterdam3D dataset. Radii used for MOBA were 1.5, 2.5, 5 and 10 meters.
In figure 5, some qualitative results are shown as well. From left to right, we can see the (1) colored input point cloud, (2) ground truth segmentation, (3) segmentation result of RandLA-Net without MOBA and (4) segmentation result of RandLA-Net with MOBA. As visible, the application of MOBA has a positive effect on the segmentation quality of minority classes. For example, in case b, it is visible that the segmentation result with application of MOBA results in the correct labeling of the whole traffic sign, while the segmentation result without application of MOBA is partly mislabeled as a street light.
Figure 5: Qualitative semantic segmentation results of multiple minority class objects using RandLA-Net. From left to right: colored input point cloud, ground truth, segmentation result of RandLA-Net without MOBA and segmentation result of RandLA-Net with MOBA.
Conclusion and future work
In this blog post we presented Multi-Scale Object-Based Augmentation (MOBA). MOBA is a new method to improve the semantic segmentation quality of minority class objects in imbalanced urban point clouds, and can therefore improve semantic mappings of urban areas and aid in asset management of topographical properties. A blog post on a project that utilizes MOBA to improve asset management in Amsterdam is coming later this year, so stay tuned!
Future research could focus on optimizing the radius configuration of MOBA to ensure the highest possible gains in semantic segmentation quality of minority class objects. Furthermore, the number of augmented point clouds per minority class generated by MOBA could be refined to improve the semantic segmentation results of these objects.
Our code, and the full report are available on GitHub. Don’t hesitate to contact us if you have any suggestions or ideas about this project.
source: amsterdamintelligence.com