Last year, you probably read a lot of our updates about the Amsterdam for All project and about the issues that we set to tackle. Now, in a series of blog posts, it’s finally time to dive into some more technical details behind the pilots that we did together with our interns. Today, we start with the topic of Venue Accessibility, and more specifically with Jeroen van Wely’s approach to step detection and Lizzy da Rocha Bazilio’s pipeline for summarizing accessibility information from online reviews.
If you’ve been following our blog, then you might have already read how we selected all of our pilots through a number of design thinking workshops. One of the biggest challenges that people with disabilities encounter in the city is that whenever they go to a location (a restaurant, a library, or any other public building), the process of determining in advance whether they can reach the place, if they could enter it and whether they would feel comfortable inside is too long and not reliable.
Journey map of wheelchair users in the Netherlands when choosing a new restaurant to go (some people might jump some steps depending on their needs)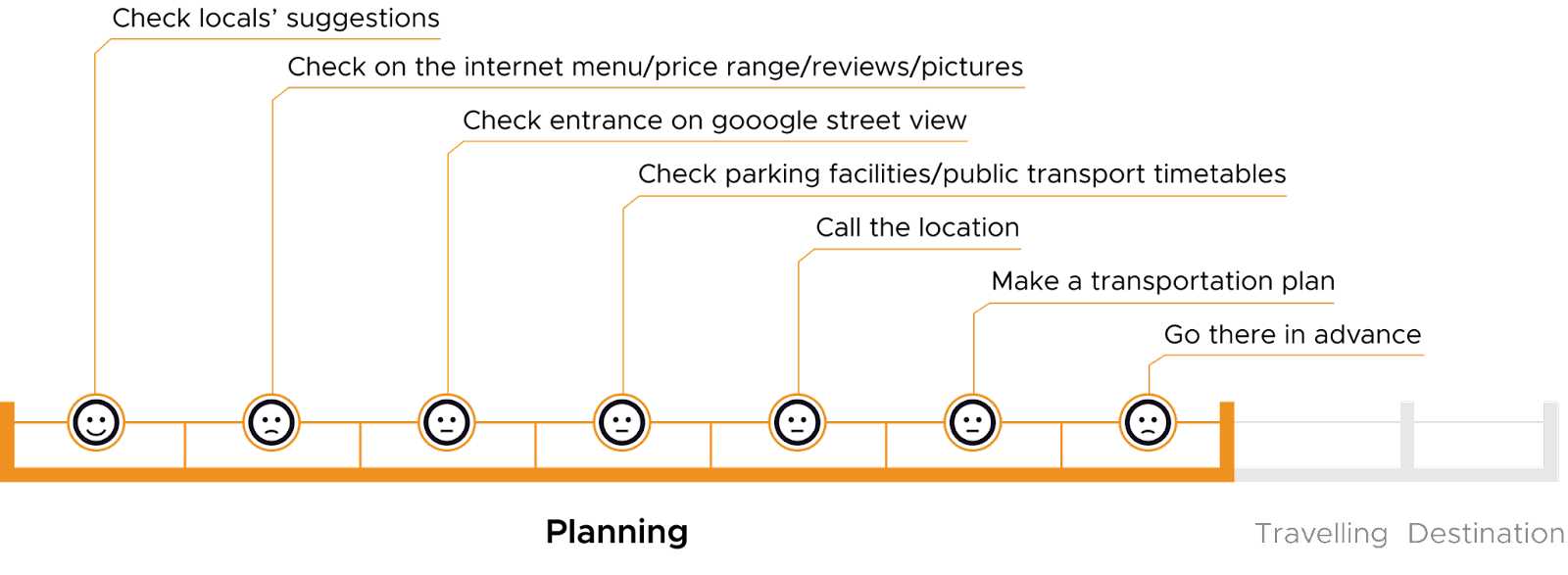
The issue is manyfold - information is often unavailable or scattered over multiple platforms that only focus on certain accessibility aspects. Furthermore, information is often available for certain locations only, and it’s mostly entered manually by users. Finally, the people who work in these venues do not always know how to answer accessibility-related questions, so even calling might not help.
Thus, we decided to explore different ways to automatically collect the required information from data sources available for plenty of locations in the city.
Information requirements that people with different disabilities need to decide if a venue is suitable for them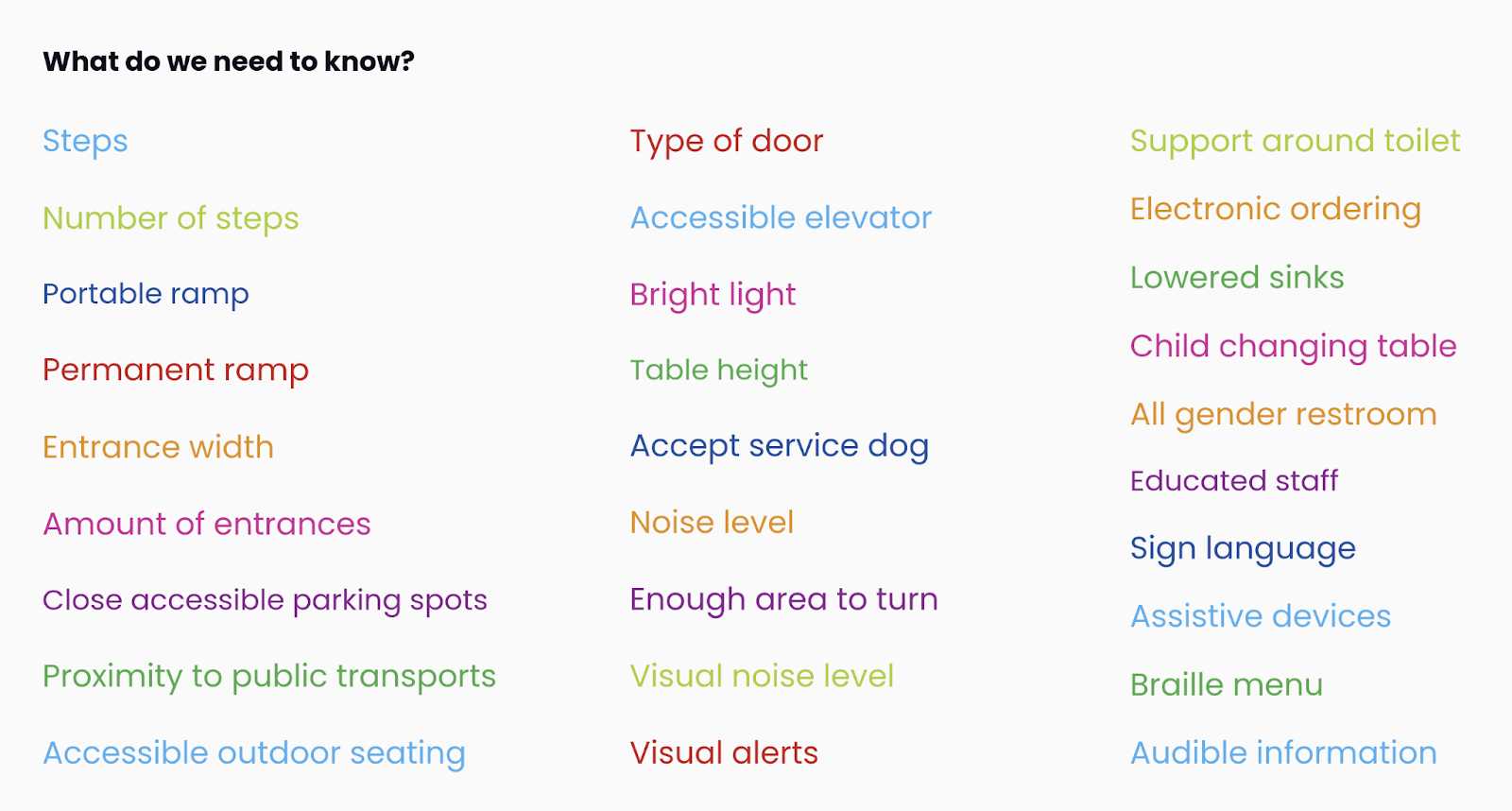
Entrance Accessibility
Provided that people can even make it to their desired destination, the first big question that arises is whether they can go inside. Depending on the physical abilities of people or whether they use a wheelchair, a baby stroller or some other assistive device, it might be important to know what kind of door there is, how wide the entrance is, whether there are steps, how many of them, and how high each one of them is, whether there is a ramp and what its inclination is.
The above-mentioned characteristics can all be seen in images. But while we have tons of experience with detecting objects on our panorama images, there is one big downside to that - it is hard to precisely localize or measure things using them. That's why, together with Jeroen van Wely, we chose to explore the use of point cloud data for the problem of analysing the entrance accessibility of venues.
Source: Stadsarchief Amsterdam / Schaap, C.P. (1955)
Individual Step Detection and Segmentation Pipeline
The main idea behind the step detection methods proposed by Jeroen in his MSc thesis is to automatically segment the points belonging to the vertical front parts of the steps - also known as “risers”. Here, we provide a generalized summary of his pipeline.
Step 1: Detect vertical points and planes
The first part of the algorithm is about finding points which are part of vertical planes. This could be done by using KDTree closest neighbour search (provided by Open3D) and computing the normal vectors at all points. Next, by using the data representation proposed by [1], one could select points that belong to planes having the right height to potentially be a step.
Step 2: Finding and merging connected components
After finding the initial set of points belonging to vertical planes, one could find groups of points that lie close to each other - that is, connected components. Due to the sparsity of the data, it could sometimes be that a step ends up being split into multiple connected components which need to be merged. This can be done by first fitting planes through the points of the connected components using the RANSAC algorithm [2]. Next, the angle and distance between the resulting planes could be used to merge components which potentially belong to the same surface.
Step 3: Point recovery and final filtering of steps
Many stair points might have been filtered in the previous steps due to noise in the data. Therefore, the final steps of the algorithm ensure those points are recovered. Finally, in order to ensure that only steps are taken into account, only the groups of points which are close to the ground and have a certain height are preserved.
While Jeroen’s pipeline currently focuses on the detection of steps, in the future we could extend it to also detect ramps or to extract other entrance characteristics.

Final output after point recovery and filtering of points that are close to the ground and are possibly consecutive steps
Indoor Accessibility
Next, once people are sure that they can go inside, they need to know whether they would also feel comfortable there: is there enough space to move around, is the toilet accessible, is the lighting suitable for their vision or is there a loud noise that they won't be able to tolerate? Due to the diversity of requirements, it's impossible and not practical to provide a single accessibility score as most automated approaches do. Furthermore, existing models often focus on extracting information from images, which puts a limit on the information we can possibly extract and provide.
Online reviews on the other hand are widely available and contain plenty of details about the available services and the experiences of different people. However, they are typically flooded by feedback related to the food, staff or other services provided by the corresponding venue. Thus, together with Lizzy Da Rocha Bazilio, we worked on a pipeline for extracting accessibility information from online reviews. The end goal is to create venue profiles that would allow people to only see a summary of the most important positive or negative statements related to certain aspects.
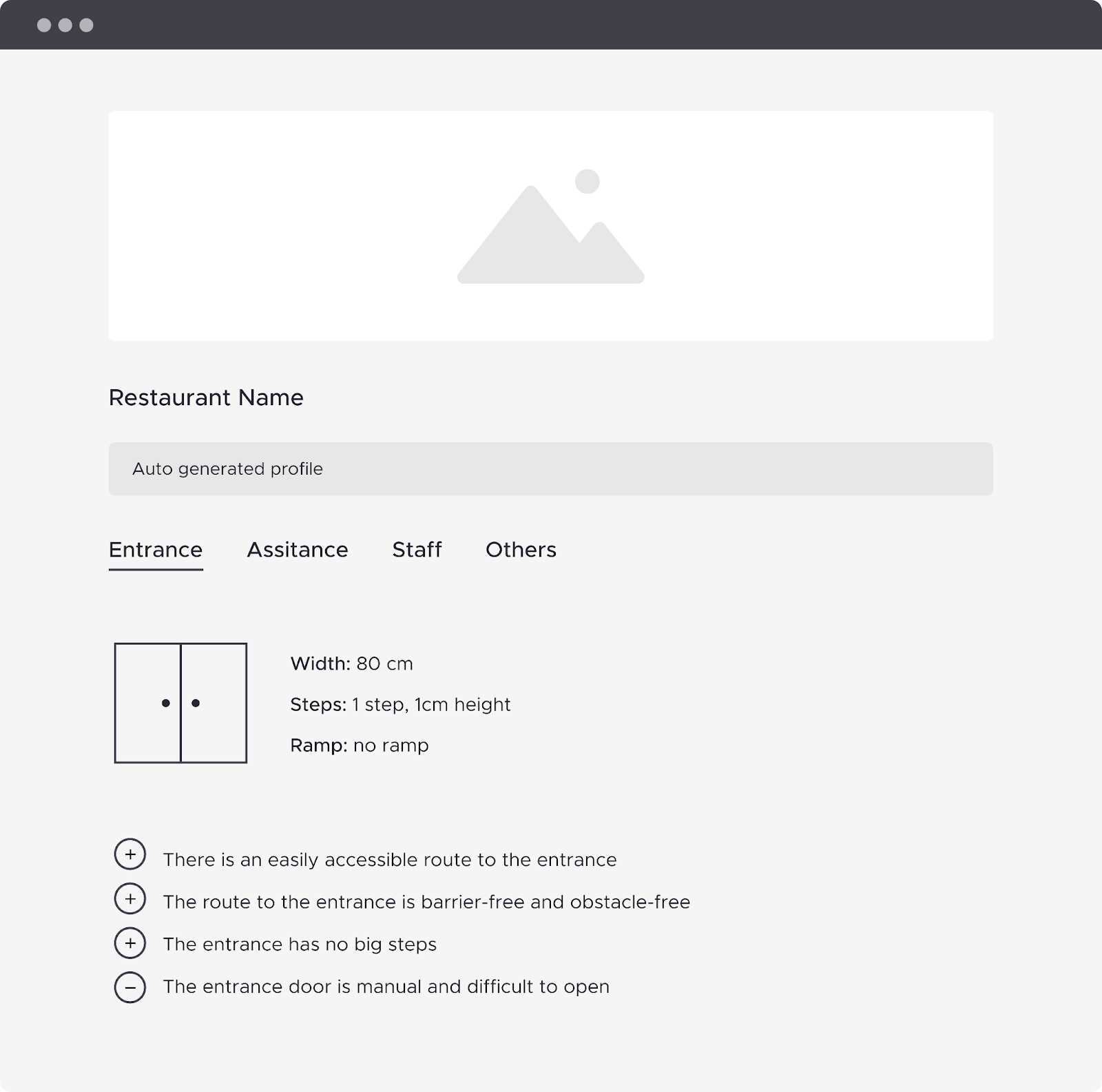
Example of a venue profile automatically generated by extracting information from point clouds or online reviews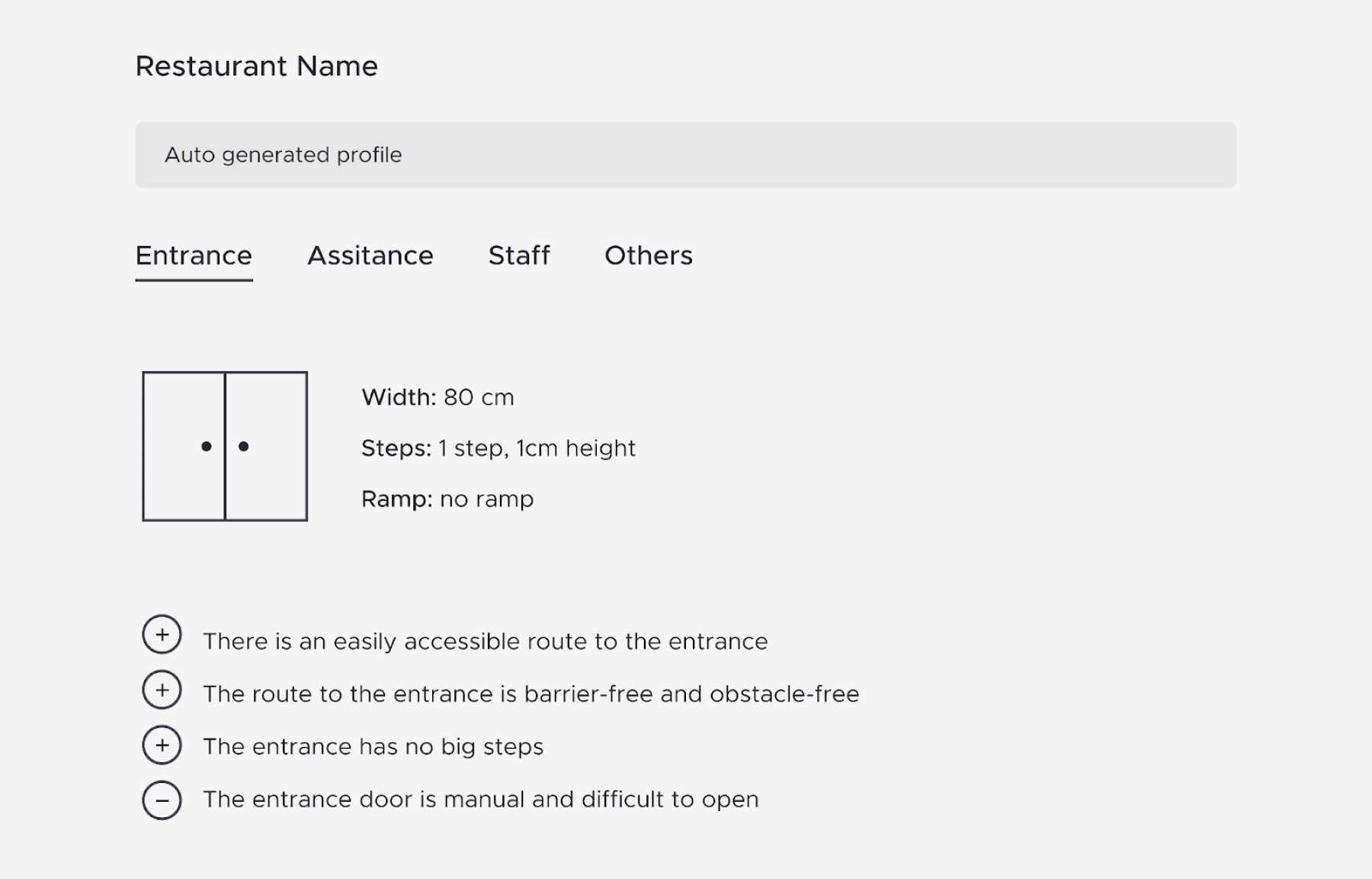
Aspect- and Sentiment-based Opinion Summarization Pipeline
Inspired by existing pipelines for product review analysis [3], Lizzy proposed the following pipeline for mining accessibility information in her MSc thesis.
Step 1: Aspect Classification
The first step of the pipeline is to split all reviews into individual sentences and determine the (accessibility) aspect to which each sentence relates. For this step, Lizzy experimented with multiple supervised approaches, as well as unsupervised setups which would allow us to more easily add new aspects of interest on the fly in the absence of big amounts of labelled data. In her work, Lizzy experimented with statements related to 5 aspects: the overall accessibility experience of the venue, access, transport & parking, the helpfulness of the staff, and accessibility of the toilets. However, the model can be easily extended to other categories such as sound or visual noise levels, availability of assistive devices, braille menus, etc.
Step 2: Sentiment Analysis
The next step of the pipeline is to determine the sentiment of each statement. Similarly to the aspect classification, Lizzy experimented both with supervised and unsupervised approaches. Unsurprisingly, her experiments showed that models based on the state-of-the-art language model BERT [4] clearly outperformed more traditional approaches such as e.g. TF-IDF [5] and doc2vec [6].
Step 3: Summarization
The final step of the pipeline is to summarize all statements. This is done per aspect and sentiment - e.g. all positive statements related to the accessibility of the toilets of a certain venue are summarized together. Lizzy experimented with multiple extractive summarization approaches - TextRank [7], as well as 3 models based on the language model BERT. We are yet to evaluate the generated summaries with actual users to determine their potential quality in an accessibility platform.
From Euan's Guide to Google Reviews
In order to be able to evaluate different approaches for the individual components of her pipeline, Lizzy conducted her research using data from the dedicated accessibility platform Euan’s Guide. This eases the task as all comments on the platform are already related to accessibility. This year we will work with Mylène Brown-Coleman, a BSc AI student from the Vrije Universiteit, on applying Lizzy’s pipeline on Google Places reviews. This would require additionally detecting only those statements that are related to accessibility within a large pool of irrelevant reviews related to the food or ambience in a location.
Next Steps
Next, we would like to share the data extracted by Lizzy, Mylène and Jeroen’s work. Just like for our whole Amsterdam for All project, this has two different purposes. On the one hand, we would like to share the extracted information with citizens so that they can make more informed decisions and better plan their activities in the city. On the other hand, we would like to share our insights with city officials, as well as owners and directors of venues and public buildings. In this way, we hope to improve accessibility in our city via a change of policy and the direct reconstruction of inaccessible locations.
* Cover Image source: Stadsarchief Amsterdam / Ruig, Chris de (1930-2013)
References
[1] Sinha, Arnab, Panagiotis Papadakis, and Mohan Rajesh Elara. "A staircase detection method for 3D point clouds." 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV). IEEE, 2014.
[2] Fischler, Martin A., and Robert C. Bolles. "Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography." Communications of the ACM 24.6 (1981): 381-395.
[3] Angelidis, Stefanos, and Mirella Lapata. "Summarizing opinions: Aspect extraction meets sentiment prediction and they are both weakly supervised." arXiv preprint arXiv:1808.08858 (2018).
[4] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[5] Salton, Gerard, and Christopher Buckley. "Term-weighting approaches in automatic text retrieval." Information processing & management 24.5 (1988): 513-523.
[6] Le, Quoc, and Tomas Mikolov. "Distributed representations of sentences and documents." International conference on machine learning. PMLR, 2014.
[7] Mihalcea, Rada, and Paul Tarau. "Textrank: Bringing order into text." Proceedings of the 2004 conference on empirical methods in natural language processing. 2004.
Source: amsterdamintelligence.com
This research was conducted by Lizzy Da Rocha Bazilio and Jeroen van Wely in collaboration with AI Team, Urban Innovation and R&D, City of Amsterdam.
Involved civil servants: Cláudia Pinhão, Daan Bloembergen & Iva Gornishka.