As part of the Amsterdam for All initiative, the city is working on improving digital accessibility for its citizens. Textual information of all sorts is released by the municipality to inform citizens. This is done through letters, posts on official government websites, factsheets and more. Often the content of these texts can be semantically difficult. As a result, the City of Amsterdam is performing research into text simplification (TS) as a method to help clarify texts for citizens. Text simplification is a process used to automatically reduce the complexity of textual information. Using TS systems improves accessibility for all citizens by reducing the cognitive load required to digest information from text. Research has proven the benefits of such systems, especially for citizens who are second-language speakers [1], or those with cognitive and/or language disorders [2, 3, 4]. Over the course of my internship at the City of Amsterdam, I investigated two TS methods, a Pivot-method and a Large Language Model approach and compared their usefulness in two complex Dutch domains.
Research
Several methods of TS have been produced since research into the field began. Among these are data-driven methods which treat the problem not as a simplification task, but as a machine translation task. Normally, text simplification would involve converting a complex Dutch sentence into a simpler Dutch sentence by modifying syntactic and lexical elements of the text. However, with the machine translation approach, we aim to translate the sentence from a source language (complex Dutch) to a target language (simplified Dutch). To do so in an end-to-end system, we require a monolingual simplification corpus: a dataset containing complex Dutch sentences to their simplified counterpart. Unfortunately, such a corpus does not exist in Dutch, as a result we experiment with other methods. In particular we research the pivot approach, which leverages the resources of another language (English) to perform this simplification.
Pivot Approach
Figure 1: Schematic overview of the pivot approach.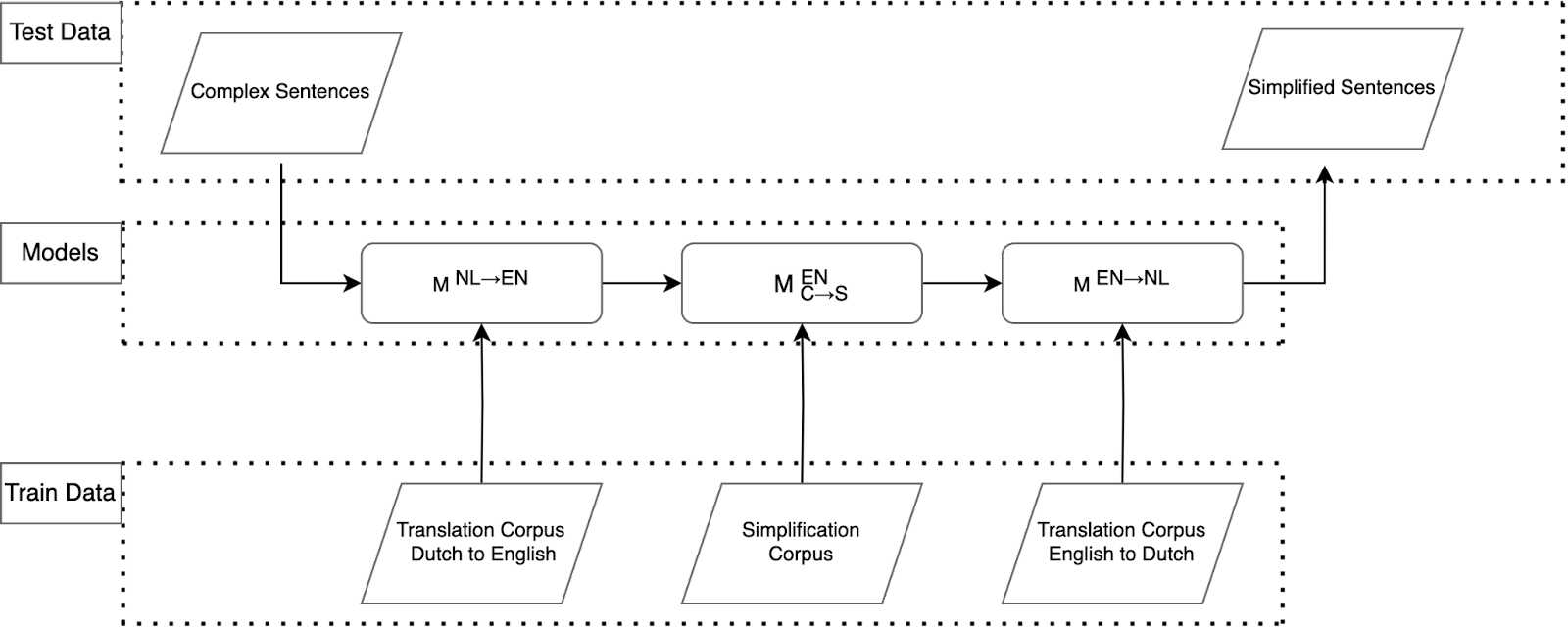
The pivot approach consists of three neural machine translation models chained together as indicated in Figure 1. The first model translates complex Dutch to complex English sentences. These sentences are then simplified in English by the second model. The simplified English sentences are finally translated back to Dutch by the final model. The output of the system should be simplified Dutch sentences, which are then evaluated. There are several benefits to using a pipeline like this. For one, it allows us to forgo the need for a Dutch monolingual simplification corpus; a severe bottleneck in our research. Additionally. the pivot pipeline allows for analysis of intermediate results from the individual models, which can help us decipher where problems arise.
We conducted several experiments to test the performance of the pivot method using different training data setups for the translation models. These experiments included concatenating datasets as well as extracting in-domain subsets from a large general corpus. Concatenating datasets was done to provide more training data which should significantly impact the results achieved in low-resource environments. On the other hand extraction of in-domain subsets is performed to generate more sentence pairs that are useful for the specific domain of simplification: in our thesis municipal and medical. This extraction was done using two separate encoding methods. This is done by encoding in-domain sentences using either a TF-IDF vectorizer or a BERT-based vectorizer and mapping them onto a vector space. Sentences from a large general corpus (Opensubtitles) are also mapped using the same encoding method. The N-nearest opensubtitles sentences to the in-domain sentences are extracted such that we have a final extracted in-domain subset of approximately 1 million sentences. The TF-IDF method encodes sentences in such a way that words that are “important” to the domain are weighted more heavily. This means the results should contain sentences with more exact in-domain vocabulary matches. On the other hand, the BERT-based method encodes sentences based on their semantic meaning. This means extracted sentences should contain sentences which align better with the target domain.
Large Language Model Approach
One of the more popular topics as of late in AI is the large language model (LLM). Advances in the ability of LLMs like ChatGPT have made them more suitable for all sorts of natural language related tasks such as summarisation, translation and simplification. In our work, we investigate the use of Large Language Models as a tool for text simplification. To do so we use the OpenAI API to simplify sentences using GPT 3.5 Turbo, a LLM designed as a conversational chatbot which has gained significant popularity recently. This approach forgoes using a monolingual simplification corpus and instead the model is able to infer simplicity, even if complex to simplified Dutch is a previously unseen language pair. To simplify text we prompted the model to “Simplify the following sentence in Dutch: [Sentence]”. In further work with the model we could explore the effects of varying specificity in prompts as well as the ability to finetune the model on a small amount of training. We compare the LLM approach to another end-to-end approach, the zero-shot approach. The zero-shot baseline is a single NMT model trained on the same data as the pivot baseline. Prior to training, all data is concatenated with a token that specifies to which language that sentence is linked. For example, the source sentence for the corpus used as training data for simplifying english text will be concatenated with a <2ensimp> token.
The implementation of our LLM and pivot methods are available on github for reproducibility.
Evaluation
We compare the results of both the LLM and the pivot-based approach in two complex domains: Dutch medical text and Dutch municipal text. In the medical domain we have a test set used in previous work to compare our results to as a baseline [5]. Since no previous work has been done in the municipal domain we do not have a baseline. Instead we compare the data setups and identify patterns herein. We use a custom test set, extracted from official letters issued by the city of Amsterdam, which contains sentences before and after being simplified by professional editors. We base our results on a number of commonly used machine translation and text simplification metrics. Among these are BLEU, SARI and METEOR, which compare our system’s output against the reference outputs from the test set.
Results
We can infer several conclusions based on the results we achieved in both the Dutch medical and municipal domain.
Dutch Medical Domain
In the medical domain we found that, with regard to the data setups of the pivot pipeline method, concatenating an extracted, in-domain corpus to a publicly available in-domain corpus provided the best results. This can be seen in the table below. The pivot pipelines are denoted as PS (pivot setup) where the superscripted information refers to the training data used for the initial translation model (English to Dutch) and the subscripted information refers to the training data used for the final translation model (Dutch to English).
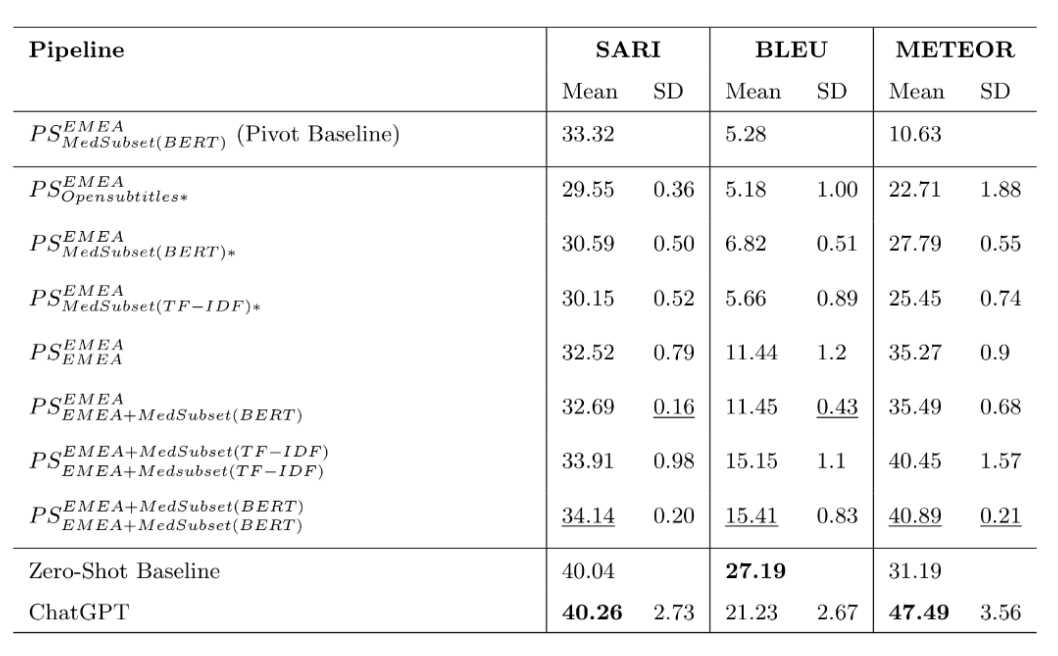
These results indicate that concatenation of data improved the results of the pivot pipeline in all three metrics, with the best results of any pivot pipeline coming from the last pivot setup. This setup concatenated a publicly available in-domain dataset (EMEA) to an in-domain dataset that was extracted from the opensubtitles corpus (MedSubset(BERT)). This concatenated dataset was used for both the training of the initial and final models in the pipeline. The results here infer that extracting sentences based on semantic similarity (using a BERT method) provides better training data than extracting based on exact vocabulary matching (TF-IDF method). Our best scoring pivot pipeline setup outperforms the baseline to which we compare in all metrics as well.
While improvements are made in the pivot pipeline, we found the best results in this domain to be from the end-to-end systems. Both the baseline and the ChatGPT simplification systems score higher than the best performing pivot model in all metrics. Here, the zero shot baseline outperforms ChatGPT in BLEU score but not SARI and METEOR.
Dutch Municipal Domain
In the municipal domain similar results are obtained. With regard to the Pivot approach, here too, we found that extracting in-domain corpora boosted results that we achieved in all metrics. Once again concatenating this data to a publicly available in-domain corpus scored highest in all metrics. This further strengthens our belief that extraction based on semantic similarity provides better training data for the pivot models than extraction based on vocabulary matches. The results for the municipal domain are presented in Table 2.
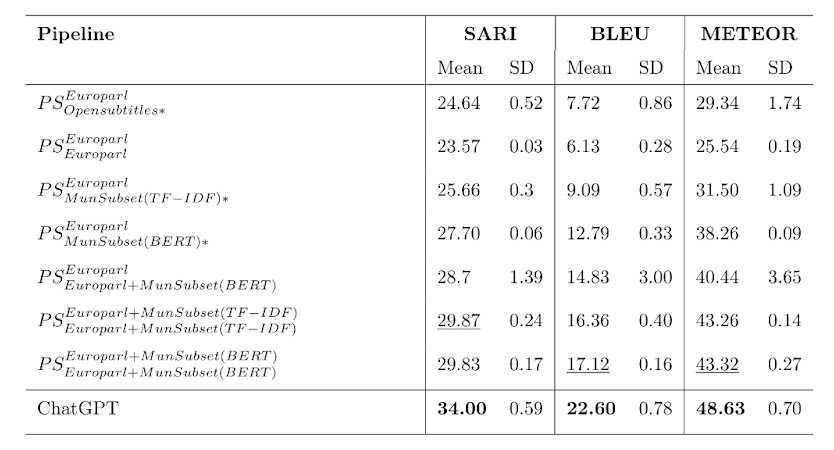
Here too, we can see that the scores obtained by ChatGPT outperform those obtained by our pivot models.
Discussion
In our work, we found the LLM approach to consistently outperform the pivot based approach in both domains. This indicates that the LLM approach is better given the currently available data. However, the variance between the ChatGPT results and the best-performing pivot based approach is not incredibly large. While this would require the production of a new dataset, we have some suspicion that, given an in-domain Dutch monolingual simplification corpus, an end-to-end model could perform as well as, if not better than ChatGPT. One reason we believe so is because of the limitations of the pivot approach. The pivot method is susceptible to errors which propagate through the pipeline. These errors cause deteriorating results. This is especially the case with errors made earlier in the pipeline as they have greater opportunity to fester. Given a suitable corpus we would only need to train one model and could achieve significantly improved results without using a LLM. This would be valuable as training a single NMT model is significantly less computationally expensive and takes less time to train compared to the LLM and the pivot approach.
Familiarising myself with text simplification and its literature, some things have become clear. First, it is difficult to accurately portray the usefulness of different approaches and systems without manual examination of simplifications. This is of course very resource intensive and not scalable. The reason for this is that the metrics that are commonly used in TS are not actually suitable. For example, the BLEU, SARI, and METEOR metrics (which we too use) generate a score based on the similarity of text to some reference output. This means that simplifications which are phrased differently will be heavily punished despite being valid simplified sentences. These metrics are thus not able to capture the full scope of simplifications.
Readability metrics such as fk-score estimate the simplicity of text but they have several limitations also. The fk-score metric is too crude to accurately measure simplicity as it fails to take many factors of simplicity into account. For example, sentences constructed in the passive voice are known to be more complex than those in the active voice. A change in voice could not be detected by the fk-score metric as it only takes into account the number of words per sentence and the number of syllables per word. As such it is also not suitable on its own, but could still be a valuable factor for a more general metric. In further work we would like to explore options to create a metric for simplicity. This method could take into account lexical and grammatical factors. For example, word simplicity could be estimated based on the frequency of words in a general corpus.
References
[1] Willian Massami Watanabe, Arnaldo Candido Junior, Vinícius Rodriguez Uzêda, Renata Pontin de Mattos Fortes, Thiago Alexandre Salgueiro Pardo, and Sandra Maria Aluísio. Facilita: reading assistance for low-literacy readers. In Proceedings of the 3327th ACM international conference on Design of communication, pages 29–36, 2009.
[2] Luz Rello, Ricardo Baeza-Yates, Stefan Bott, and Horacio Saggion. Simplify or help? Text simplification strategies for people with dyslexia. In Proceedings of the 10th International Cross-Disciplinary Conference on Web Accessibility, pages 1–10, 2013.
[3] Richard Evans, Constantin Orasan, and Iustin Dornescu. An evaluation of syntactic simplification rules for people with autism. Association for Computational Linguistics, 2014
[4] John A Carroll, Guido Minnen, Darren Pearce, Yvonne Canning, Siobhan Devlin, and John Tait. Simplifying text for language-impaired readers. In Ninth Conference of the European Chapter of the Association for Computational Linguistics, pages 269–270, 1999.
[5] Marloes Evers. Low-Resource Neural Machine Translation for Simplification of Dutch Medical Text. PhD thesis, Tilburg University, 2021.
*Cover photo by Tom Hermans on Unsplash.