This research was conducted by Willem van der Vliet in collaboration with the AI Team and the 3D Amsterdam team of the City of Amsterdam.
Involved civil servants: Daan Bloembergen & Niek Ijzerman.
Supervisors: Daan Bloembergen & Holger Caesar.

The OVL project contributes to the management of light poles in Amsterdam and to increase safety, reduce nuisance, increase fairness, reduce the use of resources (including energy) and improve aesthetics. It does this by identifying (the properties of) all individual light poles in Amsterdam.
Digital twins (DTs) are a common way for city planners and citizens to visualize impact of new policy decisions, simulate scenarios, and plan for disasters. The more detail these DTs have, the more useful they can be. Windows and doors, also known as building openings, are a critical detail missing in Amsterdam’s DT. While previous works use images, this paper investigates the usefulness of a lidar-based point cloud for building opening detection by proposing a pipeline to this end.
This paper creates a dataset for semantic segmentation and a dataset for instance segmentation for window and door classes. We begin with isolating individual buildings from larger scans using their footprint accessed from a government building database. Then, each building cloud is passed to a RandLA-Net neural network for point-wise semantic segmentation. After inference, the cloud passes through an internal false positive rejection (IFPR) module that makes use of the building footprint to rectify incorrectly labeled points in the building’s interior. Then, points are clustered into instances by an adaptive DBSCAN algorithm that derives information from data inherent to each point cloud. This pipeline shows promising results on a small-scale dataset, detecting window and door points with a mIoU of 37.81, and 40.57, respectively. Post-processing yields a 3D IoU score of 77.1 for windows and 81.32 for doors in the ideal inference case.
This paper tackles the main challenges of lidar-based building opening detection and discusses ways to mitigate these challenges in future work.
This research was conducted by Willem van der Vliet in collaboration with the AI Team and the 3D Amsterdam team of the City of Amsterdam.
Involved civil servants: Daan Bloembergen & Niek Ijzerman.
Supervisors: Daan Bloembergen & Holger Caesar.
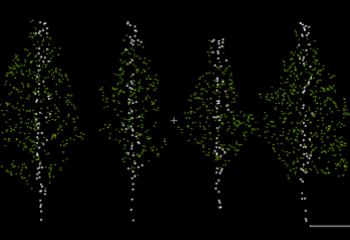
Vegetations are a vital part of our daily lives and are crucial for urban planning and the continuity of ecosystems. Accurate identification and delineation of individual trees in point cloud data is an important task in a variety of fields, including forestry, urban planning, and environmental management.
In this study, we have access to the Actueel Hoogtebestand Nederland (AHN) dataset, a publicly available high-resolution point cloud dataset generated by aerial laser scanning (ALS) throughout the Netherlands. The dataset that we will be using as the starting point for this study was previously labeled by the Amsterdam Intelligence team, with all tree points classified.
In this report, we present 2 different approaches for identifying individual trees. Both of the methods initial delineation is based on utilizing a KD-tree algorithm (Bentley, 1975) and vectors to make tree clusters. The first method identifies local maxima within a designated region through analysis of point density in that area. The second method uses some parameters to further split or merge the clusters.
A blog post summarizing the contributions can be found on amsterdamintelligence.com.
The related code is available here.
This research was conducted by Jorges Nofulla in collaboration with the department of Research and Statistics (Onderzoek en Statistiek, O&S) and the AI Team, Urban Innovation and R&D, City of Amsterdam.
Involved civil servants: Nico de Graaff & Daan Bloembergen
Supervisors: Sander Oude Elberink, Michael Ying Yang, Nico de Graaff & Daan Bloembergen

One of a municipality’s responsibilities is to regularly monitor suspended streetlights and cables for a safe and reliable environment. Mobile laser scanned 3D point clouds offer a great potential for creating high-precision digital representations of assets in street scenes. The goal of this thesis is to develop a computationally efficient and reliable pipeline that automatically detects suspended streetlights in urban scene point clouds.
In this thesis, we discuss the relevance of the problem to the municipality, review related work in object extraction from point clouds, present and describe our four-staged pipeline for the extraction of suspended streetlights and cables, and provide an extensive evaluation in terms of performance and applicability.
This research provides four contributions to the field of point cloud processing: a robust cable extraction algorithm. Second, a cable type classifier, an algorithm that can detect cable attachments, and a labelled training dataset for supervised machine learning models.
This research was conducted by Falke Boskaljon in collaboration with AI Team, Urban Innovation and R&D, City of Amsterdam.
Involved civil servants: Daan Bloembergen & Chris Eijgenstein.

Recently, the City of Amsterdam has been using urban point clouds as a data source for a variety of projects. Urban point clouds are a valuable data asset for the City because they hold high quality and rich information on assets in the public space. Previous projects that utilized urban point clouds as data source to extract useful information about the city include the detection of overhanging street lights and cables and extraction of venue accessibility.
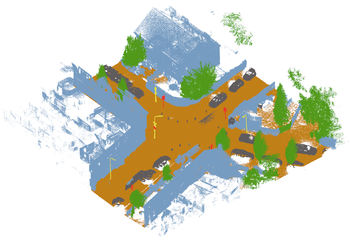
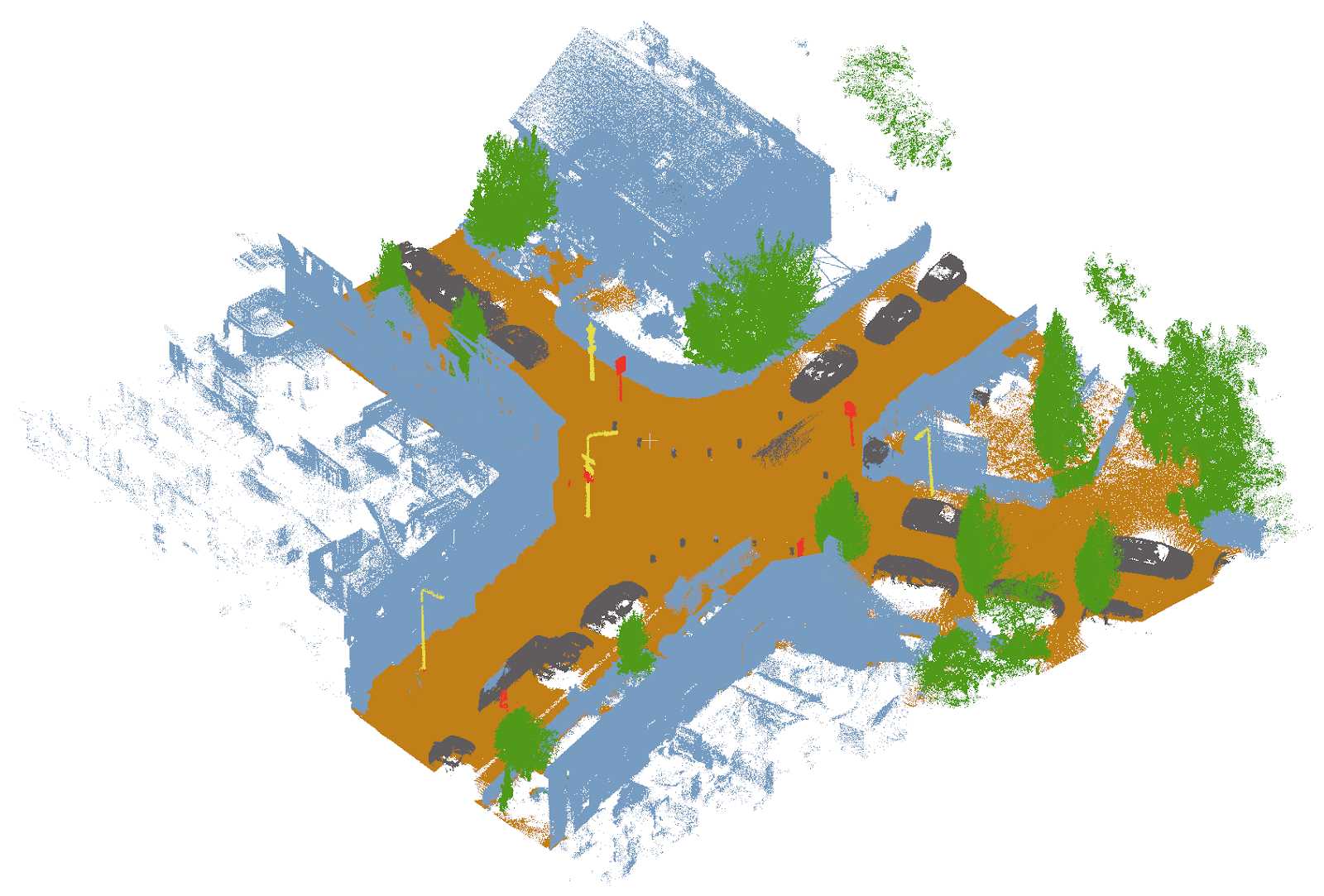
Another key interest of the City is to semantically segment urban point clouds to generate mappings of urban topographical object properties. From these mappings, useful insights can be gathered. For example, information on the region-based density of parked cars or misalignment of traffic lights on roadsides can be collected. An example of a segmented urban point cloud is shown in figure 1.
To generate semantic mappings from point clouds, semantic segmentation models can be applied. The goal of these segmentation models is to correctly assign each point in the point cloud a semantic label. This semantic label describes the semantic class a point belongs to. To be able to correctly assign these labels, segmentation models randomly sample points in point clouds. Subsequently, the spatial and/or color information of these points is utilized to learn a discriminative point feature which is used to classify the point.
Figure 1. Example of segmented urban point cloud.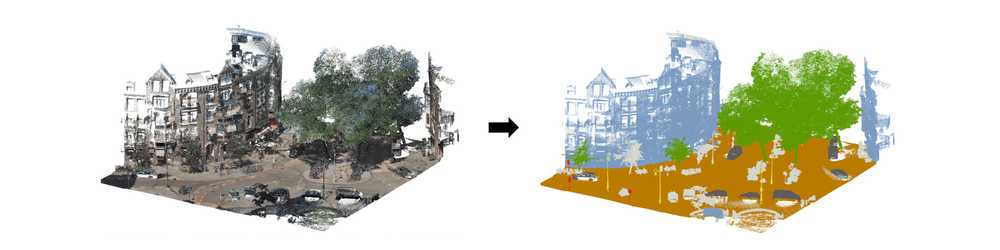
A difficulty when training semantic segmentation models on urban point clouds to generate semantic mappings of the city, however, is that urban point clouds are frequently affected by class imbalance. Class imbalance refers to the situation where certain classes dominate others. For example, most points in points clouds that are collected in Amsterdam belong to big objects and surfaces like buildings and roads, while the number of points belonging to relatively small objects in point clouds such as rubbish bins is significantly lower. These circumstances complicate the learning of useful features for points belonging to minority class objects since there is less data to learn from. Accordingly, the segmentation quality of minority class objects is relatively low (see figure 2). Existing methods like importance sampling and global augmentation could be applied to resolve the class imbalance problem. However, due their speed and efficiency limitations, these are usually impracticable to apply to large-scale imbalanced urban point clouds.
Figure 2: example of how class imbalance can affect segmentation quality of minority class objects. The well-represented ground points are segmented almost perfectly, while almost all minority class rubbish bin points are misclassified as car points.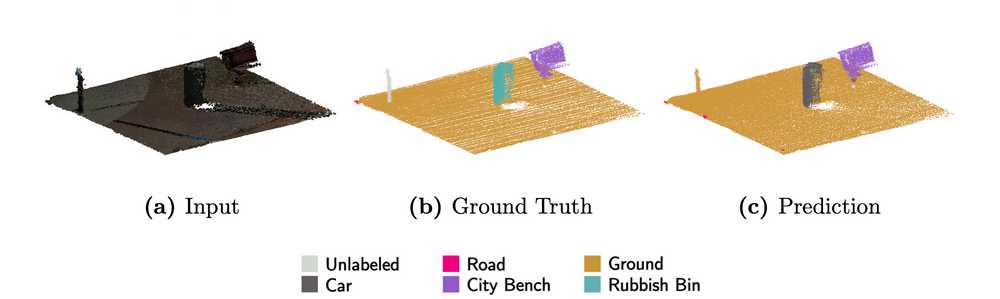
Motivated by the fact that the City of Amsterdam is interested in generating high quality semantic mappings of the city using segmentation models, but this procedure is affected by class imbalance and existing solutions to this problem show limitations, the goal of this project was to develop an efficient method to encounter the class imbalance problem in semantic segmentation of urban point clouds. To this end, we developed Multi-Scale Object-Based Augmentation (MOBA). This is a memory-efficient method to improve the segmentation quality of minority class objects in urban point clouds.
In this blog post, we first explain the MOBA framework. Second, we elaborate on the experimental setup that was used to test MOBA. This includes a description of the utilized point cloud dataset, deployed deep-learning-based semantic segmentation models and evaluation metrics. Third, we present and discuss the results. We conclude this blog post with a reflection on the results and recommendations for future work.
MOBA is an augmentation technique specifically designed to increase the semantic segmentation performance of deep-learning-based models on objects belonging to minority classes. In general, MOBA comprises three steps, which are stated below:
Figure 3: A visualization of MOBA applied to a city street light with four radii: 1.5, 2.5, 5 and 10 meters. For distinctiveness, the streetlight has been marked yellow.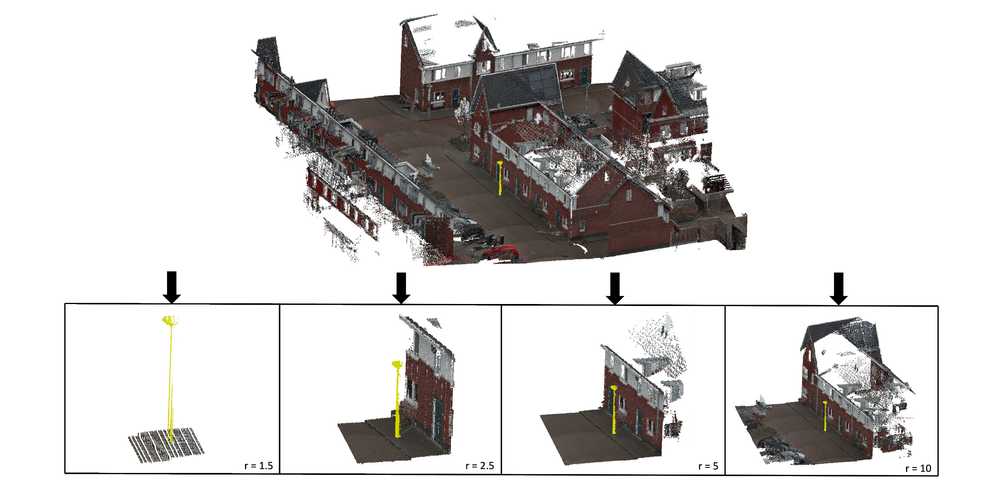
MOBA can be considered as an efficient method to improve the semantic segmentation quality of minority class objects for two reasons: (1) the method does not add to the computational complexity of the model compared to alternative sampling methods like importance sampling and (2) the additional memory required for the augmented tiles is limited as only small cropped tiles are added to the dataset. This memory efficiency is beneficial when working with limited memory resources and large-scale urban point cloud datasets that can easily reach hundreds of gigabytes.
A large-scale imbalanced urban point cloud dataset of Amsterdam named Amsterdam3D was utilized to test MOBA. This dataset consists of 140 point cloud tiles of 50m x 50m. By default, each point in the dataset holds geographic (i.e., X,Y,Z coordinate values), multi-spectral (i.e., R,G,B color values) and intensity (i.e., a reflectance value) information. In total, there are 10 semantic classes. An overview of these classes and the imbalanced distribution of points over these classes are shown in table 1 and figure 4, respectively.
Table 1: Quantitative representation of Amsterdam3D dataset. Number of points is given in millions.
Figure 4: Distribution of points over all scans in Amsterdam3D dataset. Scale is logarithmic.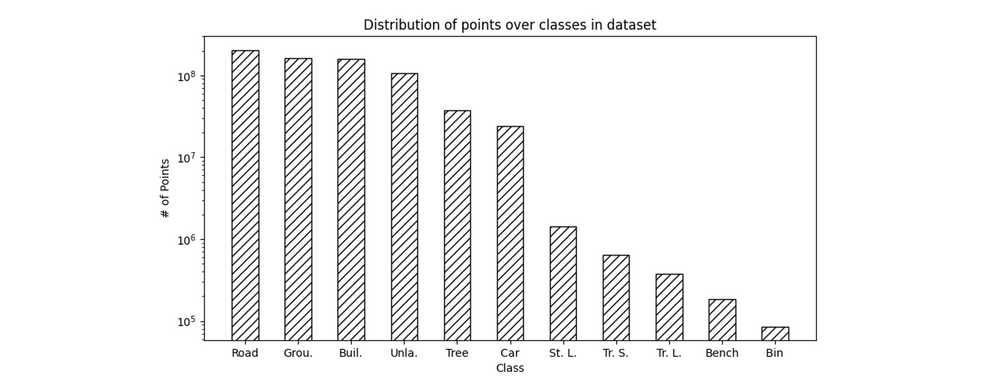
Three models named RandLA-Net, SCF-Net, and CGA-Net were deployed to test and evaluate MOBA. The reason these models were utilized is twofold. Firstly, the proposed models have proven their power on multiple benchmark datasets by reaching remarkably high performance compared to other models. Secondly, their random sub-sampling architecture to learn point features allows the processing and segmentation of the large-scale urban point cloud dataset we used. In contrast, many competitors cannot handle such data due to memory limitations.
Intersection over Union (IoU) and mean Intersection over Union (mIoU) were used as the primary evaluation metrics. IoU measures the fraction of correctly classified points in class c over the total number of points classified as class c or belonging to class c. mIoU is the average mIoU over all classes. The IoU and mIoU formulas are given in equations 1 and 2. Furthermore, mean precision (mP) and mean recall (mR) were also included as evaluation metrics.
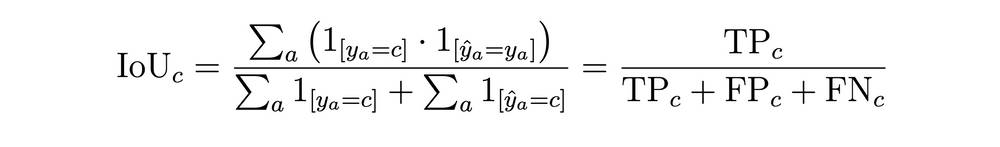
Equation 2: mean IoU.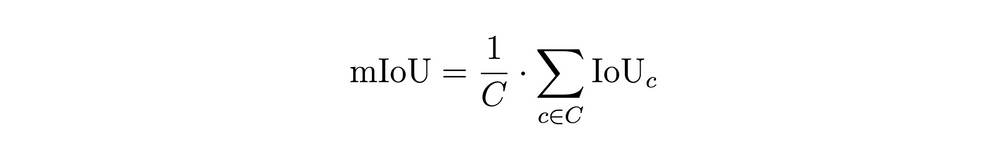
Table 2 shows the quantitative results of MOBA. As can be seen, the IoU of multiple minority classes (e.g., street light, street sign, traffic light and rubbish bin) show significant improvements in IoU when MOBA was applied. Specifically, the rubbish bin class shows remarkable increases from 15.1% up to 78.1% in IoU. Furthermore, the mR score is highest across all models when MOBA is applied. This characteristic can be considered desirable since a decrease in false negatives (i.e., a higher mR) suggests that all models generate better point features to correctly identify most points, including minority class points.
Table 1: Quantitative semantic segmentation results without and with MOBA on Amsterdam3D dataset. Radii used for MOBA were 1.5, 2.5, 5 and 10 meters.
In figure 5, some qualitative results are shown as well. From left to right, we can see the (1) colored input point cloud, (2) ground truth segmentation, (3) segmentation result of RandLA-Net without MOBA and (4) segmentation result of RandLA-Net with MOBA. As visible, the application of MOBA has a positive effect on the segmentation quality of minority classes. For example, in case b, it is visible that the segmentation result with application of MOBA results in the correct labeling of the whole traffic sign, while the segmentation result without application of MOBA is partly mislabeled as a street light.
Figure 5: Qualitative semantic segmentation results of multiple minority class objects using RandLA-Net. From left to right: colored input point cloud, ground truth, segmentation result of RandLA-Net without MOBA and segmentation result of RandLA-Net with MOBA.
In this blog post we presented Multi-Scale Object-Based Augmentation (MOBA). MOBA is a new method to improve the semantic segmentation quality of minority class objects in imbalanced urban point clouds, and can therefore improve semantic mappings of urban areas and aid in asset management of topographical properties. A blog post on a project that utilizes MOBA to improve asset management in Amsterdam is coming later this year, so stay tuned!
Future research could focus on optimizing the radius configuration of MOBA to ensure the highest possible gains in semantic segmentation quality of minority class objects. Furthermore, the number of augmented point clouds per minority class generated by MOBA could be refined to improve the semantic segmentation results of these objects.
Our code, and the full report are available on GitHub. Don’t hesitate to contact us if you have any suggestions or ideas about this project.
source: amsterdamintelligence.com

Obstacles in the sidewalk can often block the passage and prevent pedestrians from completing their daily tasks in adequate time and effort. Furthermore, the city registries are outdated or manually added, so there is no way to inform citizens about the best routes to follow and help city officials to have an overall image of sidewalk accessibility to improve it. The purpose of this paper is to suggest an automatic and scalable way to measure sidewalk obstacle-free width using point clouds.
Involved civil servants: Cláudia Pinhão, Chris Eijgenstein, Iva Gornishka, Shayla Jansen, Diederik M. Roijers, Daan Bloembergen
Presented at the workshop "The Future of Urban Accessibility for People with Disabilities: Data Collection, Analytics, Policy, and Tools" as part of the ASSETS'22 conference.
Cite as: Pinhão, C. F., Eijgenstein, C., Gornishka, I., Jansen, S., Roijers, D., & Bloembergen, D. (2022). Determining Accessible Sidewalk Width by Extracting Obstacle Information from Point Clouds. ASSETS'22 workshop on The Future of Urban Accessibility.
Steden worden drukker, lastiger om te onderhouden, dus we zoeken naar nieuwe manieren om dat beter te kunnen doen. Een van de technieken is puntenwolken en daar vertellen we je graag meer over.
Puntenwolken zijn een reeks datapunten in de ruimte. Deze punten geven een 3D-weergave van de omgeving. Een puntenwolk is te vergelijken met een foto waarbij ook de locatie van de pixels wordt meegenomen bij het verzamelen van gegevens. Om deze gegevens te verzamelen, gebruiken we LiDAR-scanners op voertuigen, zoals auto's, boten of fietsen. Deze technologie stelt ons in staat om de exacte locatie van objecten te detecteren en hun breedte, diepte en hoogte vast te kunnen leggen. Deze gegevens geven ons waardevolle informatie over de straten van Amsterdam. Deze informatie kan worden verzameld, opgeslagen en gevisualiseerd met behulp van AI.
Aan het begin van het project wilden hebben we een puntenwolk van de stad laten inwinnen. Een opname van de puntenwolk van heel Amsterdam die we nu hebben is 763 GB, en bestaat uit 136 miljard punten. Daarnaast is er de puntenwolk van Weesp: 40 GB, 7 miljard punten. Vanwege de grote omvang van deze puntenwolk gingen we op zoek naar manieren om dit te analyseren en om te zetten in nuttige informatie. Het puntenwolk project begon als onderdeel van Mobile Mapping, wat valt onder de afdeling Basisinformatie. Mobile Mapping is de techniek waarbij een voertuig met speciale apparatuur 3D-beelden maakt van de omgeving. Hiervoor gebruiken we auto’s, boten, fietsen en andere voertuigen. Met deze technologie is het mogelijk om van ieder object op de 3D-foto de exacte positie en afmetingen te bepalen.
De afdeling Basisinformatie houdt zich voornamelijk bezig met het inwinnen van ruimtelijke data met behulp van mobiele sensoren. Het doel van Basisinformatie is om LiDAR-data nog breder binnen de gemeente in te kunnen zetten.
De gemeente zou deze data bijvoorbeeld kunnen gebruiken voor het lokaliseren van straatmeubilair, het monitoren van de gezondheid van bomen en voor het verrijken van 3D-modellen. Ook voor toegankelijkheid biedt de puntenwolk mogelijkheden. Zo kunnen we door middel van de puntenwolk in kaart brengen hoe breed de stoep is, en of deze niet te steil of beschadigd is. Het wordt hiermee dus mogelijk om bijvoorbeeld voor de hele stad uit te rekenen welke lantaarnpalen scheef staan, en hiermee te voorkomen dat ze omvallen en kosten en gevaarlijke situaties te vermijden.
Deze toepassingen van nieuwe technologieën in de verschillende projectteams van de gemeente geven een positief vooruitzicht voor het komend jaar. Het afgelopen jaar werd de meeste LiDAR-data van de stad in de vorm van puntenwolken in combinatie met panoramafoto’s opgeslagen en beheerd in een registratie. Dit geldt overigens ook voor 3D-data die vanuit de lucht werd ingewonnen. In de toekomst zou het zelfs mogelijk kunnen zijn om de staat van het meubilair te herkennen. Wellicht kan de technologie worden ingezet om de kwaliteit van registraties te verbeteren met behulp van LiDAR en AI.
Wil je meer lezen over Mobile Mapping? Neem dan een kijkje op : Mobile Mapping - Gemeente Amsterdam
Amsterdam draagt zorg voor de staat van de openbare ruimte. Een van de verantwoordelijkheden van de gemeente is het bijhouden van een actueel register van grootschalige topografische objecten zoals gebouwen, wegen en waterwegen, maar ook kleinere objecten zoals straatnaamborden, straatlantaarns en vegetatie. In Nederland gebeurt dit door middel van de Basisregistratie Grootschalige Topografie (BGT). Het bijhouden van deze registratie is arbeidsintensief en vatbaar voor menselijke fouten.
Onlangs heeft de gemeente Amsterdam een 3D puntenwolk op straatniveau aangeschaft die het gehele gemeentelijke gebied omvat. De puntenwolk is opgenomen met behulp van zowel een fotocamera als een LiDAR sensor, wat resulteert in een puntenwolk die niet alleen coördinaten bevat, maar ook kleurinformatie. Binnen het team van Amsterdam Intelligence is er een proefproject opgezet om nauwkeurige locatie- en hoogte details van de straatverlichting van Weesp te verzamelen. Een eerste stap in dit project is het wegfilteren van punten die tot de grond behoren. In dit artikel vertellen we je er meer over.
One of the responsibilities of a municipality is to maintain an up-to-date record of large-scale topographical objects such as buildings, roads, and waterways, but also smaller objects such as street signs, street lights, and vegetation. In The Netherlands this is the “Basisregistratie Grootschalige Topografie (BGT)”. Maintaining this record is labour-intensive and susceptible to human error. Nowadays, accurate data sources are available to aid in this task.
Recently, the City of Amsterdam has acquired a street-level 3D Point Cloud encompassing the entire municipal area. The point cloud, provided by Cyclomedia Technology, is recorded using both a panoramic image capturing device together with a Velodyne HDL-32 LiDAR sensor, resulting in a point cloud that includes not only <x, y, z> coordinates, but also RGB data. In order to investigate the potential of using this data to help improve the topographical register a pilot project has been set-up within the AI Team. The goal of the pilot is to extract accurate location and height details of the street light inventory of Weesp, in order to facilitate the upcoming merger of these two municipalities.
One of the challenges of working with point clouds is the large volume of data. For example, a typical 50x50m urban scene can easily be in the order of 100 MB. A large portion of this can be attributed to ground points, which is why a first pre-processing step in many point cloud classification approaches is to filter out (or label) these ground points in order to simplify further operations.
In this blog post, we describe our findings of efficiently extracting ground points from the input point cloud.
In our research we looked at the ground segmentation algorithm for LiDAR point clouds by Zermas et al¹. The ground non-ground segmentation algorithm utilises the assumption that the ground is planar in most cases. A plane is estimated using deterministically assigned seed points in an iterative fashion. Once the plane is estimated, a thresholding is applied on the LiDAR points to discriminate whether a point belongs to the ground or not. The main advantage of this method is the low computational cost. However, this method does not perform well for scenes with large ground fluctuations as shown in the animation below.
Implemented in C++, this algorithm takes approximately 2.9 seconds for a 50x50m point cloud tile of 2.5 million points on a 2020 i7 CPU.

In order to overcome the limitations of plane-based ground filters we investigate the possibilities of using available elevation data and overlaying this data on the point cloud. For this, we use the AHN3 or “Actueel Hoogtebestand Nederland”, the openly available elevation model of the Netherlands obtained by aerial laser scanning. A so-called “maaiveld” layer is provided, in which non-ground objects such as buildings and vegetation have been removed.
The image above shows the result of overlaying the AHN3 surface (shown in yellow / purple) on top of the point cloud. The elevation data matches the ground points quite accurately, however gaps appear in the AHN data which are caused by, for example, vehicles on the road. We include an additional pre-processing step in which small gaps in the AHN data are filled using interpolation. After this, points in the point cloud which are within a certain margin of the AHN surface (e.g. +/- 25 cm) are labelled as “ground”.
Implemented in Python, these two steps take approximately 0.3 seconds for a 50x50m point cloud tile of 2.5 million points on a 2020 i7 CPU.
The animation below shows the performance of both ground filtering approaches. The video shows a 50x100m segment of roughly 4.5 million points. The two filtering approaches are compared by colouring the extracted ground points brown and the non-ground points green. It is clear from this visualisation that the plane-fitting approach (at 4 seconds in the video) is not able to handle a scenario in which the ground is build-up of multiple planes with varying height, such as the elevated road in this case. The AHN-based ground filter (starting at the 8-second mark) is able to match the ground level accurately, and is also able to follow the sloped curbs.
These first experiments highlight the potential of data fusion techniques for the pre-processing of point clouds. The AHN-based method not only works better, but is also faster because it does not have to “look for” a ground plane to fit to the data. We are currently working on a similar data fusion method to extract buildings, so stay tuned!
Code for this project is available on GitHub.
[1] D. Zermas, I. Izzat and N. Papanikolopoulos, "Fast segmentation of 3D point clouds: A paradigm on LiDAR data for autonomous vehicle applications," 2017 IEEE International Conference on Robotics and Automation (ICRA), 2017, pp. 5067-5073, doi: 10.1109/ICRA.2017.7989591.
Auteurs: Daan Bloembergen & Chris Eijgenstein
Nederlandse inleiding door: Jason Fiawo
Dit artikel is afkomstig van: Efficiently extracting ground points from street-level point clouds (amsterdamintelligence.com)
Urban street-level point clouds provide a rich source of data that can potentially be used to accurately map the public space. Applications include localising street furniture and extracting relevant properties, monitoring tree health, enriching 3D models, and mapping accessibility by measuring sidewalk clearances and localising ramps, just to name a few.
These applications share a common requirement: we need to know which pixel belongs to which type of object, a problem that is commonly known as semantic segmentation. Recent years have seen an increasing interest in this topic in the scientific community, leading to a range of semantic segmentation algorithms, typically based on deep learning.¹ A prerequisite for using such deep learning algorithms is the availability of large datasets to train on.
A major challenge when dealing with point clouds, however, is precisely the lack of publicly available general purpose annotated datasets. Even when such datasets are available, variations in building style, types of vegetation, and other location-specific details make it hard to translate results from one dataset to another. Therefore, many of these applications still require the creation of a custom annotated dataset as a first step. Manually annotating point clouds can be quite cumbersome and time-consuming, however, which creates a substantial hurdle to take before even starting to work on actual algorithmic solutions.
In this blog post we built on previous work in which we extracted ground and buildings from such point clouds using smart data fusion with public data sources such as elevation data and topographical maps. We summarize previous results, and explain how we additionally label cars, pole-like objects, and trees. Finally, we give a sneak-peek into some first results of training a deep semantic segmentation model on our annotated dataset.
Note: we presented this project at the 10th International Workshop on Urban Computing, and a paper² describing our approach in detail is available on arXiv.
Our point cloud, provided by CycloMedia, encompasses the municipal area of Amsterdam and Weesp. For now, we focus our attention on Weesp alone. The point cloud includes <x, y, z> coordinates as well as RGB and intensity values, and is cut into 50x50 meter tiles. The Weesp area comprises roughly 3,500 tiles with a total of 7 billion points.
For our data fusion approach we use the Dutch AHN3 elevation data, BGT topographical maps, and NDW data for traffic sign locations. The image below shows examples of these data sets corresponding to the point cloud tile in the header image of this blog post.

We use these two data sources to automatically label objects of six classes: ground, buildings, cars, trees, street lights, and traffic signs. The latter three classes are processed similarly, since each is pole-like in nature and represented as a point on the topographical map. Here we only give a brief overview of the main idea, for more detail please refer to our paper or the accompanying Jupyter notebooks on GitHub.
Ground
We use the elevation data to automatically label all points within a small margin from the elevation surface as ground. The advantage of this approach is that it works for flat as well as curved surfaces.
Buildings
We use footprint shapes from the BGT topographical map to label all points within the footprint as building. Elevation data is used to limit the height. Region growing based on connected components is used to include balconies, canopies, and other protruding elements that are not included in the footprint.
Cars
Car-shaped clusters above road parts and parking bays in the BGT topographical map are labelled as car. For each cluster we compute a minimum three-dimensional bounding box, and match its dimensions to the range of expected values for typical cars.
Trees, lamp posts, traffic signs
We look for pole-shaped clusters in the point cloud close to their expected locations as given in the BGT and NDW data sources. To reduce the number of false positives we only consider matches that have a certain minimum height, and whose diameter falls within an expected range for the type of object in question.
Final step: check and correct
We manually check the resulting labels, correct small errors, and add missing objects.
An example point cloud tile labelled by our method is shown in the figure below. Note that this is before any manual correction. As you can see, many objects are labelled accurately, with no false positives. However, one tree and one street light have been missed. In the case of the tree, this is due to the fact that the stem is leaning sideways, which prevented our method from finding a vertical pole-like structure. The street light on the other hand was too far away from its expected location, and hence was ignored.

To give an indication of the reduction in human time and effort that results from our automated labelling, we (read: Chris) manually labelled a few tiles and compared this experience to simply correcting the labels in a pre-labelled tile. Manually labelling a tile takes at least one hour, while correcting small mistakes by our approach takes roughly five minutes on average, which is a 20-fold reduction.
This makes it possible to create a labelled dataset that is big enough to train a deep semantic segmentation algorithm in a matter of hours, rather than weeks. To demonstrate the potential, we (again: Chris) used our method to label 109 out of the 3,500 tiles of the Weesp dataset. Interesting to note here is that since we simply want enough labelled training examples, it does not matter if our approach misses a few objects, as long as the ones that are labelled are correct. We then trained RandLA-Net³, a state-of-the-art semantic segmentation model for point clouds, on this labelled subset using a 99/10 train/val split. Performance on the validation set is given in the table below:

Clearly the model performs very well for ground, buildings, trees, and cars. Performance is slightly lower for street lights, and even less for traffic signs. The latter is partly due to the imbalance in the dataset: street lights and traffic signs only make up 0.17% and 0.07% of the training set, in terms of number of points, respectively.
As a final example, the figure below shows a point cloud tile that was not part of the labelled dataset, and which was subsequently labelled using the trained RandLA-Net model. This further demonstrates the quality of RandLA-Net’s predictions. The majority of mistakes are objects of classes that were not included in the training data, such as small poles (bollards), fences, low vegetation, etc.
These first results show the great potential of using smart data fusion to train high quality semantic segmentation models. Our approach is particularly suited for large-scale point clouds with hundreds of millions of points, where manual annotation is infeasible. This offers great potential for cities to automate (parts of) the process of cataloguing street furniture, perform change detection, map out accessibility, and much much more.
We are currently using our method to locate all street lights in Weesp. If you want to know how that goes, stay tuned!

Resources
References
[1] Jiaying Zhang, Xiaoli Zhao, Zheng Chen, and Zhejun Lu, 2019. A review of deep learning-based semantic segmentation for point cloud. IEEE Access 7 (2019), 179118–179133.
[2] Daan Bloembergen and Chris Eijgenstein, 2021. Automatic labelling of urban point clouds using data fusion. arXiv preprint arXiv:2108.13757.
[3] Qingyong Hu et al. 2020. RandLA-Net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11108–11117.
Auteurs: Daan Bloembergen & Chris Eijgenstein
Dit artikel is afkomstig van: Automatically labelling urban point clouds using smart data fusion (amsterdamintelligence.com)

Watch this video externally on:
YouTube
In this video, we show how to label 3D point cloud data in CloudCompare software. The different steps can be followed in the following time frames:
Auteur: Chris Eijgenstein
Dit artikel is afkomstig van: How to Label a Point Cloud using CloudCompare software (amsterdamintelligence.com)

In a previous post we discussed how we can automatically filter the ground in point clouds using elevation data. Once this has been done, it becomes easier to separate the remaining points into clusters that represent various free-standing objects. However, we still need to label these clusters correctly!
In this blog post we discuss how we can automatically label buildings using a combination of BGT (a database of large topographical objects) and AHN elevation data. The reason to use both data sources simultaneously is that they complement each other: the BGT provides accurate and up-to-date 2D information, while the AHN adds a 3D aspect allowing us to take the building height into account as well.
The BGT, or basisregistratie grootschalige topografie in Dutch, is a database of large topographical objects such as roads, buildings, power lines, train lines, etc. Buildings are stored as polygons representing the building’s footprint. For each tile of our point cloud, we extract the corresponding polygons (see image below).
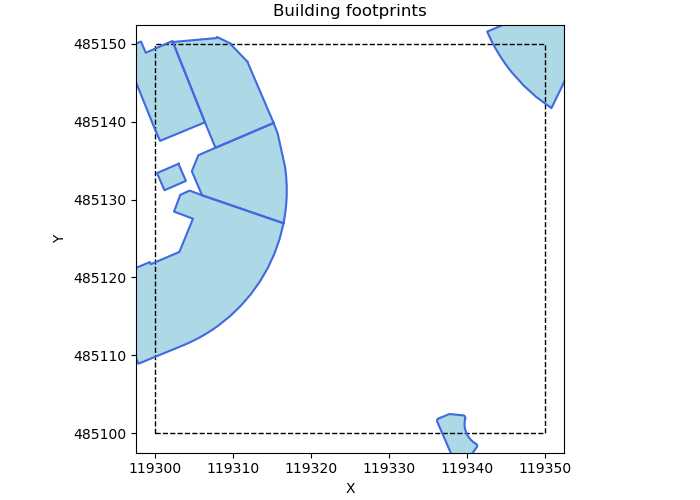
Then, we mark points that are inside this polygon (in terms of their <x,y> coordinates) as potential building points. Since both the BGT and the point cloud have a certain margin of error, we inflate the building footprint by 25cm to increase the number of points that are included. Later in this post we also discuss how we make sure that further protruding elements such as balconies are correctly labelled as well.
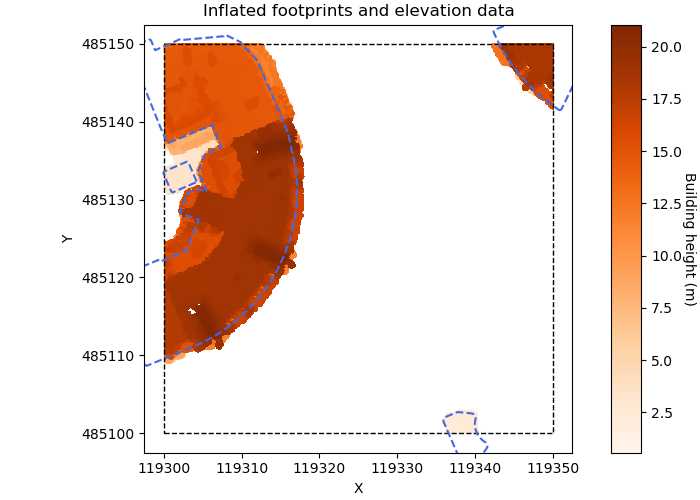
It can happen that there are points within the footprint that in fact do not belong to the building. A typical example are trees that partially overlap with the footprint where their branches overhang the building’s roof. To prevent such mistakes, we use AHN3 elevation data, which includes building elevation data, i.e. height of the roof. Similar to the ground filter we discussed previously, we extract the building height data corresponding to the point cloud tile, and use this as a cut-off (again with a 25cm margin of error) in the <z> coordinates. As such, we end up marking all points that fall within the footprint in terms of <x,y>, and are below the building’s roof in terms of <z>. The image below shows how these two data sources combine.
As mentioned before, certain protruding elements such as balconies, canopies, and bay windows (the typical Dutch erkers) are not contained in the footprint polygon. In order to include these, we use a region growing technique. One option is point-based region growing, in which for each point features are computed in order to determine whether that point should be included or not. This method is very precise, but also computationally expensive.
Since we have a very large number of point cloud tiles to process, we opt for the more efficient approach of cluster-based region growing. This method does not make a decision for each individual point, but instead it first finds connected components in the point cloud. We then mark an entire component as building if the fraction of that component that was already marked previously exceeds a threshold. To improve the accuracy of this approach, we use different settings for this threshold, as well as for the level of detail in the connected component search, for different parts of the building facade: a more cautious approach near the ground level where there is more clutter; and a coarser approach near the roof, where the point density is lower.
Finally, we label all points marked in the previous steps as ‘building’ in the point cloud. An example of the resulting labelling is shown in the animation below.
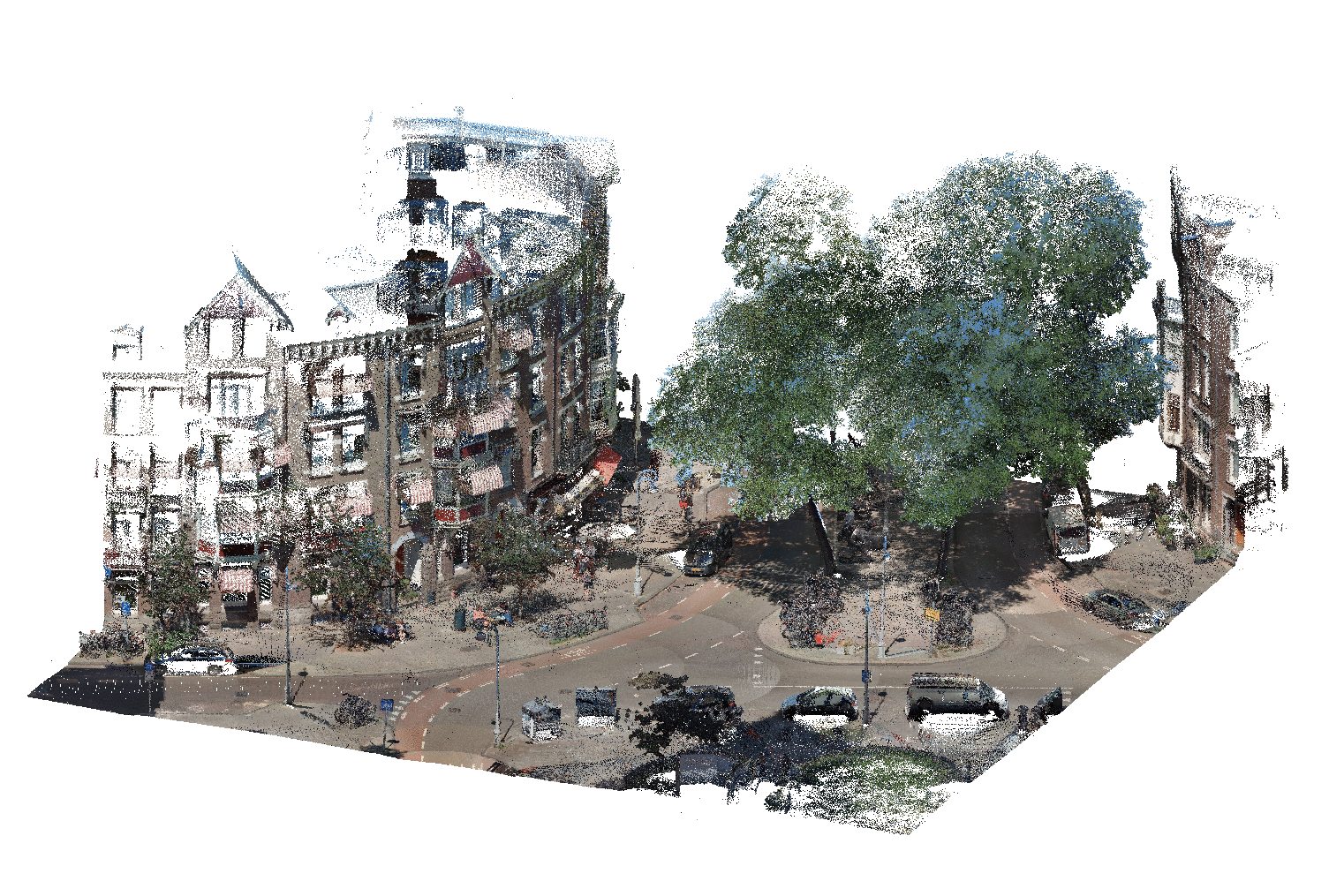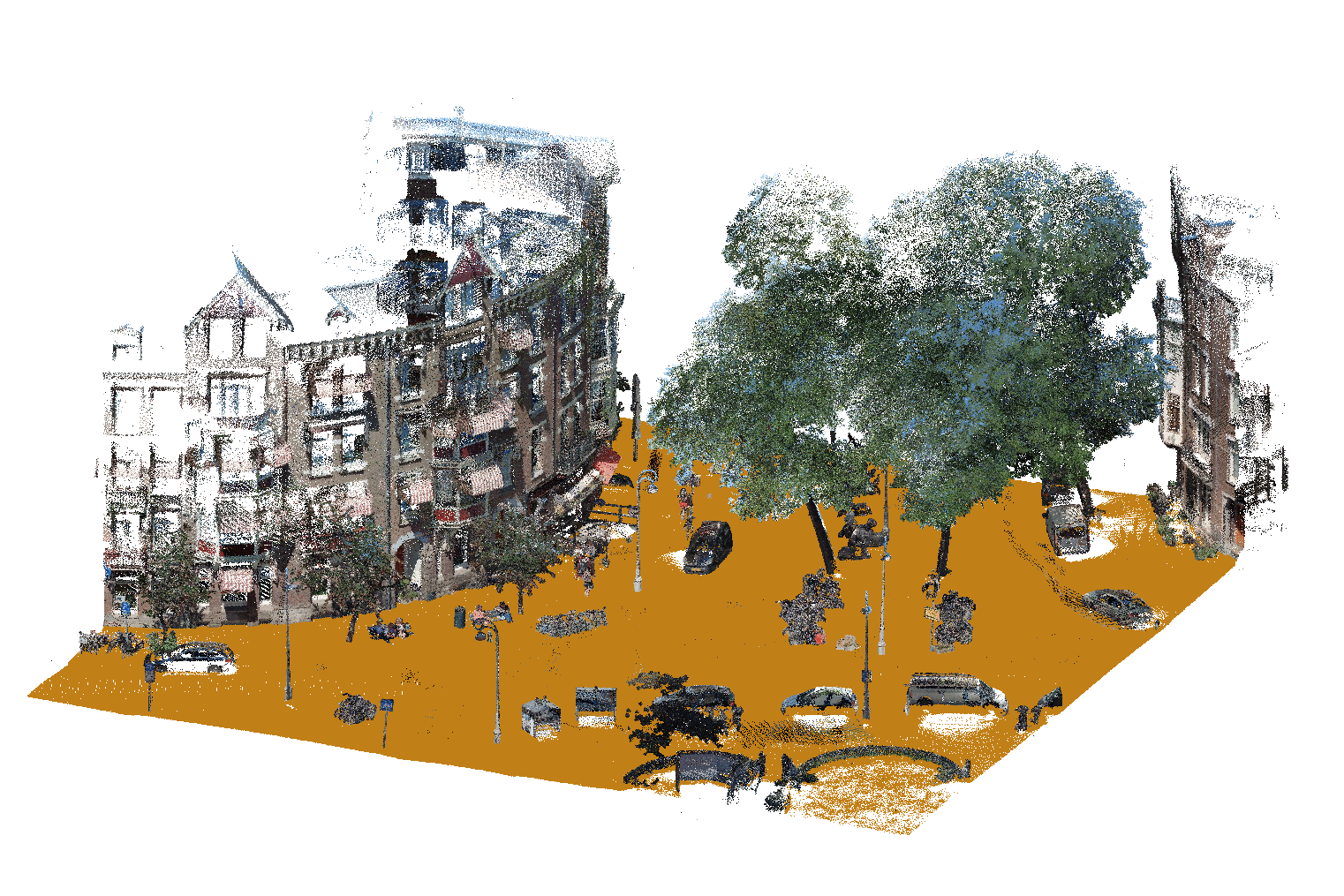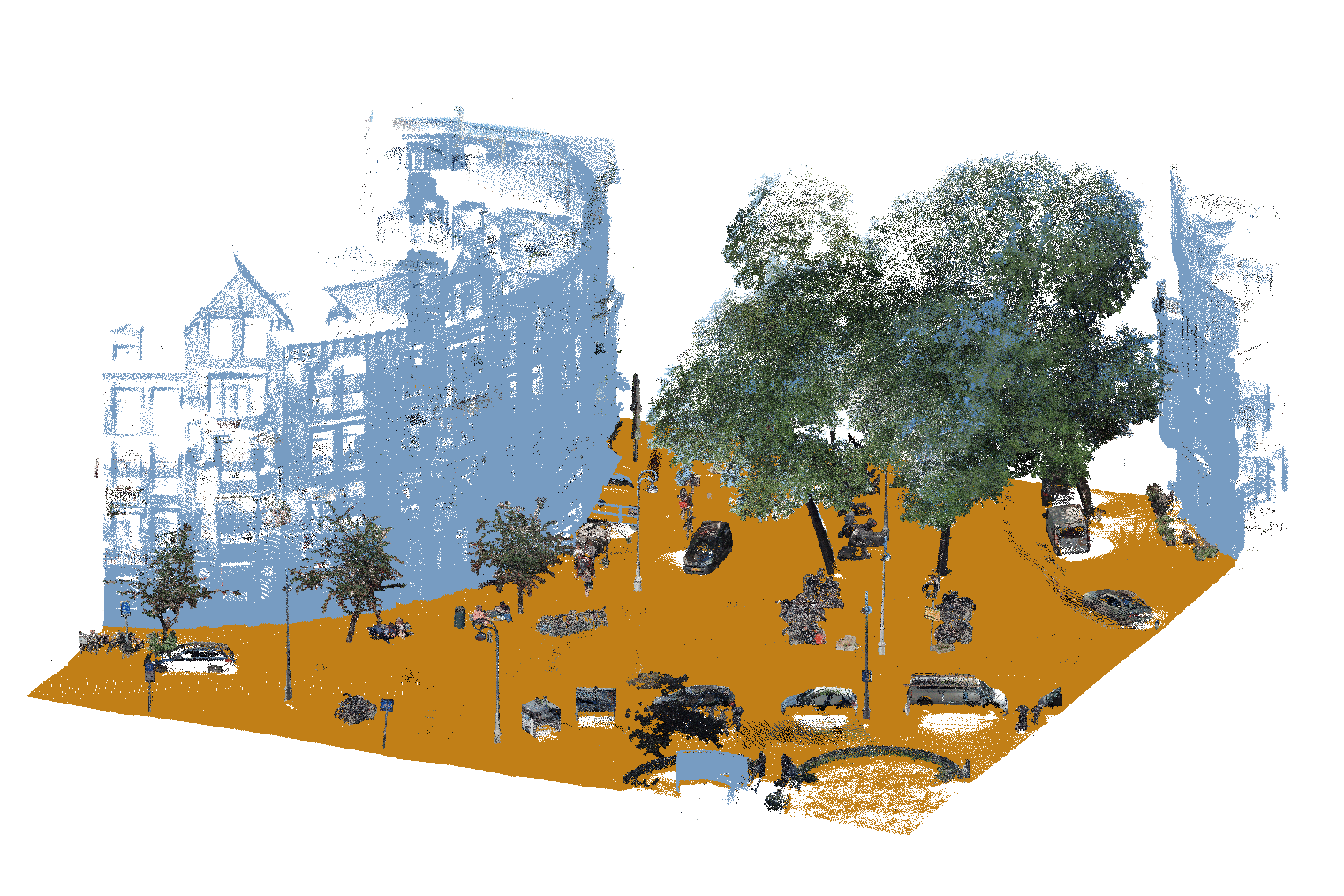
For more details and example code, see our project on GitHub. There we also provide Jupyter notebooks which explain the labelling of ground and buildings as well as the two region growing methods.
Auteur: Daan Bloembergen
Dit artikel is afkomstig van: Automatically labelling buildings in point clouds using BGT and AHN (amsterdamintelligence.com)