This research was conducted by Natali Peeva in collaboration with AI Team, Urban Innovation and R&D, City of Amsterdam.
Involved civil servants: Iva Gornishka
Supervisors: João Pereira & Iva Gornishka

The AI team of the municipality of Amsterdam is experimenting with generative AI to be able to give advice about the practical use of generative AI within municipalities.
This document shows the results of our initial comparisons of LLMs, with a special focus on open-source alternatives. It is based on literature research and running tests on municipal use cases (without tuning and with only minimal prompt engineering).
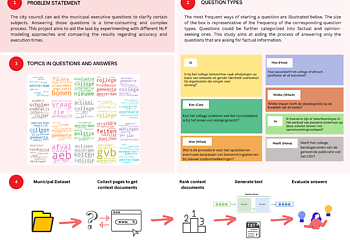
Standard approaches to question answering do not readily apply to answering complex policy-related questions. Furthermore, existing models and resources primarily focus on English and general questions.
This poster presents Natali Peeva's approach to investigating to what extent and how can state-of-the-art natural language processing models aid the answering City Council questions within the City of Amsterdam. The methodology can later be applied to any policy-related questions independent of their origin.
This research was conducted by Natali Peeva in collaboration with AI Team, Urban Innovation and R&D, City of Amsterdam.
Involved civil servants: Iva Gornishka
Supervisors: João Pereira & Iva Gornishka

Text simplification (TS) makes written information more accessible to all people, especially those with cognitive and/or language disorders. Despite much progress in TS due to ad- vances in NLP technology, the bottleneck issue of lack of data for low-resource languages still persists. To this end, we use a pivot-based approach to simplify Dutch medical and municipal text for the municipality of Amsterdam. This allows us to forego using a Dutch monolingual simplification corpus which, to our best knowledge, does not exist, in favour of using one in a higher resource language: English. We experiment with augmenting training data and corpus choice for this pivot-based approach. We compare the results to a baseline and an end-to-end LLM approach using the GPT 3.5 Turbo model. We find that, while we can substantially improve the results of the pivot pipeline, the few-shot end-to-end GPT-based simplification performs better on all metrics. With our work, we introduce a baseline for further comparison in the domain of Dutch municipal text and some improvements to the existing pivot-pipeline for simplifying Dutch medical text. Lastly, we provide a benchmark for comparing a pivot-based approach against an LLM approach.
This research was conducted by Daniel Vlantis in collaboration with AI Team, Urban Innovation and R&D, City of Amsterdam.
Involved civil servants: Iva Gornishka
Supervisors: Shuai Wang & Iva Gornishka

Many Europeans experience difficulties with reading. This can cause them to be unable to take in important information that is meant for them. For governments and institutions, it is thus important to write their texts in a way that makes them most accessible. The words that are used in these texts play an essential role in their perceived complexity. Automatic simplification of these complex words is called lexical simplification and can help increase the accessibility of texts.
Previous work on lexical simplification has relied mostly on lexical resources. The main limitations of such approaches are 1) that they cannot generate all simplifications for all complex words, and 2) that the simplifications are solely based on the complex word, not the sentence around it. This can result in unsuited simplifications. Therefore, a model for contextualized lexical simplification was introduced by Qiang et al. (2020), which does not rely on lexical resources and generates simplifications based on the context. It makes use of the contextual language model BERT to generate substitutions of the complex word. This approach achieves state-of-the-art results on common benchmarking datasets.
In this work, experiments are performed to increase the performance of this method by fine-tuning the model toward simple language generation, this way the model will produce simplifications rather than substitutions. Moreover, the possibility of fine-tuning to adapt the model to the domain of Dutch municipal texts is explored. To do so, first, a dutch variant of LSBert, called LSBertje is developed. The model is then fine-tuned to produce domain-specific simplifications. The findings of this work underline the adaptability of these contextual language models: exposure to simple language is seen to yield simpler simplification candidates. Domain-specific simplifications were not achieved, but the findings suggest that fine-tuning for domain-specific simplifications is a feasible research angle for future work.
This research was conducted by Eliza Hobo in collaboration with AI Team, Urban Innovation and R&D, City of Amsterdam.
Involved civil servants: Iva Gornishka & Cláudia Pinhão.
Supervisors: Iva Gornishka & Lisa Beinborn

Image datasets captured from public spaces are used in many applications and are especially crucial for computer vision tasks requiring real-world data. However, these datasets pose an inherent risk to the people appearing in the images and are often subject to strict privacy regulations that dictate their use and distribution. Through image anonymization, which aims to remove the identifiable aspects of people from images, we can mitigate the privacy issues associated with image datasets, allowing them to be freely shared for collaboration, future research, and peer review.
In this work, we present our research on methods of generating and evaluating realistic anonymized image datasets that can be used in a wide range of applications. We use conditional Generative Adversarial Networks to develop models for generating anonymized people in place of the identifiable people who appear in the original images. Furthermore, in the absence of an industry-standard evaluation method for person anonymization, we also propose anonymity and diversity metrics as part of a comprehensive method for evaluating the anonymity and realism of generated anonymized image datasets.
This research was conducted by Kaleigh Douglas in collaboration with AI Team, Urban Innovation and R&D, City of Amsterdam.
Involved civil servants: Laurens Samson & Iva Gornishka.
Supervisors: Laurens Samson & Phillip Lippe