The city of Amsterdam is committed to leveraging the benefits of data, but because of the responsibilities of the organization, municipal data products often involve sensitive data and can have a serious impact on citizens. It’s therefore of the utmost importance that data is used in a way that is ethical and fair towards all citizens.
This is especially important when using machine learning. Machine learning makes use of data by learning through the generalization of examples, defining rules that apply for past cases, but also predicting future unseen cases. This technique can be very useful to make data-driven decisions, uncovering relevant factors that humans might overlook, but it doesn’t ensure fair decisions.
Over the last few years, many problematic examples of machine learning made headlines, showing that it does not at all guarantee fair decisions.

At the municipality, one application of machine learning is a model that helps counteract illegal holiday rentals, freeing up valuable living space for Amsterdam citizens. In this context, we need to make sure that different groups of people are treated fairly when a suspicion of illegal holiday renting at an address arises.
In this blogpost, we’ll share with you how we went about analyzing the model for biases[¹] with the objective to prevent harmful, unjustified, and unacceptable disparities. This entails estimating the magnitude and direction of biases present in the model, understanding them, and mitigating where necessary.
The methods described in this blogpost represent how we translated the abundance of theory on bias in machine learning to practical implementation. There’s unfortunately not (yet) one perfect way to handle bias in machine learning, but hopefully, this example will inspire you and make it just a little bit easier to carry out a bias analysis yourself.
This is part 1 of three blogposts, in which we’ll start by explaining some important concepts regarding bias in machine learning. If you already feel confident in that area, stay tuned for part 2 and part 3, which cover the practical details of our methodology and the results.
Causes of bias
As we showed recently, bias in the outcomes of a model may arise in different ways. The main one is through bias in the data used to train a model. This may represent bias in the actual underlying process, or it may get introduced when data is collected, while the underlying process itself is completely unbiased - or both.
To understand this a little better, it’s useful to look at some types of bias (by no means an exhaustive list):
- Selection bias: Occurs when some types of people are more or less likely to appear in your dataset than others. An example is when the dataset consists of investigations, and people with certain characteristics were more likely to be investigated.
- Self-selection bias: May occur when subjects can influence whether they are included in the sample. An example is when someone can decide for themselves to participate in a study or not, and people with certain characteristics were more likely to pull out.
- Attrition/survivorship bias: May occur when the final dataset consists of subjects that "survived" a certain trajectory and excludes those that dropped out. An example could be the students that passed a specific course. Again, this becomes problematic if those that dropped out differ systematically from those that did not.
- Observer/societal bias: May occur when the data is based on someone's subjective judgment of a situation, as the data then potentially reflects the observer's personal biases. When cleaning the cities daily, this will create a bias of how dirty the city is, since it is something that is observed very frequently.
It can also be useful to consider bias at the modeling stage, which is commonly called inductive bias. These are the assumptions one must make in order to train a generalizable machine learning model. They may vary depending on the algorithm that is used.
Disparate treatment vs. disparate impact
Two principal doctrines exist in (US) discrimination law: disparate treatment and disparate impact. Although they are concepts from US law, they provide a useful way of thinking about bias.
Disparate treatment happens when an individual is treated less favorably than others for directly discriminatory reasons. It may occur in a model if the discriminatory category is used as a feature. This could be either directly, or indirectly but intentionally through correlations with other, seemingly neutral features (we will dive into more details in the next sections).
Disparate impact happens when seemingly neutral systems or practices are in place that, unintentionally, disproportionately hurt individuals who belong to a legally protected class. It could be introduced into a model by using features that seem non-discriminating, but still, disadvantage some protected groups.
What clearly separates disparate impact from disparate treatment is the absence of intention: selecting new colleagues based on their ability to comprehend the intricacies of Dutch municipality bureaucracy could be classified as disparate treatment if we do it intentionally to make it harder for non Dutch persons to join the municipality, or as disparate impact if we overlooked the fact that this test might be easier for a native Dutch speaker[²].
To check disparate impact, the "four-fifths" rule is often used: in historical cases, a 20%-difference between two groups has been enough to conclude that there's discrimination.
Individual vs. group fairness
Individual and group fairness are closely related to disparate treatment and disparate impact.
Individual fairness states that similar individuals should be treated similarly. This means striving for procedural fairness and equality of opportunity: people with the same relevant characteristics should get the same outcome.
Group fairness, on the other hand, states that outcomes should be equal on a group level. This means striving for distributive justice and minimal inequity: good and bad outcomes should be equally divided among protected groups, even if those groups may differ in relevant characteristics. The logic behind this is that sometimes, differences in relevant characteristics are caused by historical injustices, so outcomes should be distributed equally to prevent those historical injustices from having a lasting impact. Caution is required though, because it could have an adverse impact on a protected group if, for example, loans are given to people with lower creditworthiness, and they go bankrupt because of it.
Note how these two concepts are not necessarily compatible: to make the outcomes fair on a group level, we might need to treat individuals from a disadvantaged group more favourably than those from an advantaged group.
Roughly speaking, group fairness is the way to go if one believes that differences in characteristics and outcomes between groups are the result of historical injustices (like discrimination) that an individual cannot do anything about. Individual fairness is the way to go if one believes that the characteristics and outcomes of a person have nothing to do with their group but are the product solely of their own choices and actions.
Based on that, we can then choose to either:
- treat similar people similarly based on relevant features, given their current degree of similarity;
- treat seemingly dissimilar people similarly, based on the belief that the dissimilarity is a result of past discrimination.

Group fairness shares much of its logic with this famous illustration of equality vs. equity
(Interaction Institute for Social Change | Artist: Angus Maguire)
Direct vs. indirect bias
Direct bias means that a model discriminates by using a sensitive attribute, such as membership of a protected group, as a feature. The model can thus directly see which group subjects belong to, and directly learn any correlation between the sensitive feature and the target. The solution to direct bias is to remove sensitive attributes from the model.
Indirect bias (also called bias by proxy) happens when a non-sensitive feature is correlated with a sensitive attribute. By using this proxy variable as a feature, the model may still learn to discriminate between groups. An example that holds true in many places is that postcode is often a proxy for nationality: postcode is not inherently sensitive, but in most cities, it does have a strong relation to the nationality of inhabitants.
Indirect bias is also sometimes called "redlining", after the past practice of US credit providers to circle certain neighborhoods on a map with a red pencil to mark them as areas they would not serve. This way, they deliberately reduced the number of black people in their customer base.
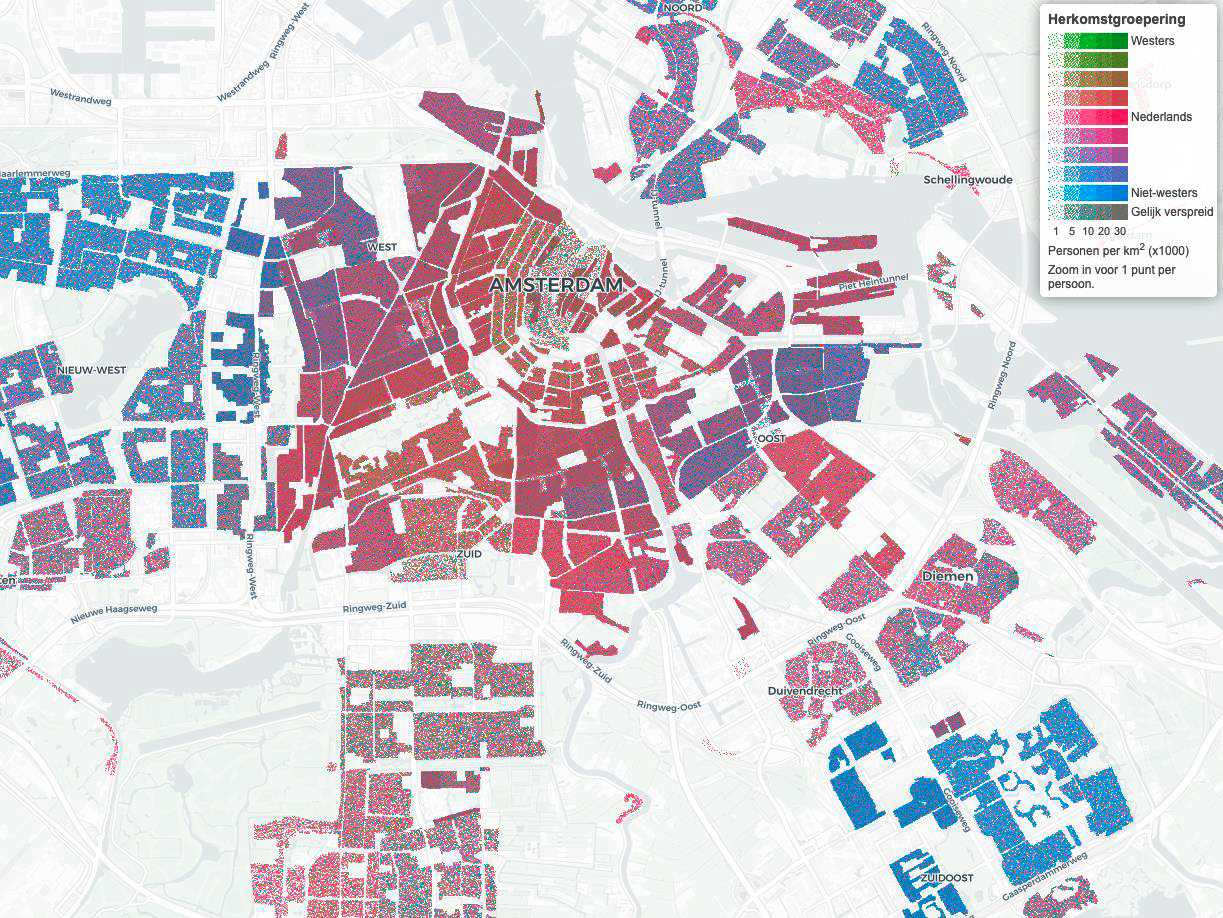
Postcode is often correlated to nationality, also in Amsterdam (screenshot from CBS visualization)
Reducing bias
Looking at the potential sources of bias, there are a few natural ways to counter it: by changing the underlying process, changing the way the dataset is collected, or adjusting the algorithm.
Furthermore, there are three stages in the modeling process where it is possible to intervene using mitigation techniques and reduce the bias:
- During the preprocessing of the data, for example, before the model is trained, features are re-weighted in favor of the unprivileged group to reduce the bias.
- During the selection/training of the algorithm, for example, using adversarial debiasing. In this technique two models are trained: one to predict the outcome based on the features, and one to predict the protected attribute based on the outcome of the first model. The goal is to ensure that from the outcome of the first model it is not possible to predict the protected attribute.
- Or as postprocessing of the predictions, for example, swapping the outcomes between privileged and unprivileged groups near the decision boundary.
Since mitigation techniques alone could easily fill a blogpost and we ended up not needing them for our model, we won’t go into more detail here.
However, in terms of practical implementation, it is good to know that many mitigation methods and fairness metrics are implemented (and described) in the AI Fairness 360 toolkit by IBM.
Conclusion
In this first part, we iterated over important concepts of bias in machine learning models, explaining the theory behind the decisions that must be made during a bias analysis. The purpose of this part is to provide a good starting point for further study and to know the basic concepts needed to understand the second part.
In the second part, we are going to get practical and look at the actual methodology that we used in our model, in order to ensure that different groups of people are treated fairly when suspicion of illegal holiday renting at an address arises.
We hope that reading both parts will inspire and help you to carry a bias analysis yourself.
Footnotes
[1] Bias is a term that can mean very different things to different people. In this blogpost, we’ll use the term loosely to describe any “harmful, unjustified, and unacceptable disparities” in the outcomes of a model.
[2] Disregarding for a moment the fact that navigating bureaucracy is indeed sometimes an indispensable skill here.
Auteurs: Sebastian Davrieux, Meeke Roet, Swaan Dekkers & Bart de Visser
Dit artikel is afkomstig van: Part 1: Concepts: Analyzing Bias in Machine Learning: a step-by-step approach (amsterdamintelligence.com)